AMD Instinct MI300X workload optimization#
2026-02-06
48 min read time
This document provides guidelines for optimizing the performance of AMD Instinct™ MI300X GPUs, with a particular focus on GPU kernel programming, high-performance computing (HPC), and deep learning operations using PyTorch. It delves into specific workloads such as model inference, offering strategies to enhance efficiency.
The following topics highlight auto-tunable configurations as well as Triton kernel optimization for meticulous tuning.
Workload tuning strategy#
By following a structured approach, you can systematically address performance issues and enhance the efficiency of your workloads on AMD Instinct MI300X GPUs.
Measure the current workload#
Begin by evaluating the performance of your workload in its current state. This involves running benchmarks and collecting performance data to establish a baseline. Understanding how your workload behaves under different conditions provides critical insights into where improvements are needed.
Identify tuning requirements#
Analyze the collected performance data to identify areas where tuning is required. This could involve detecting bottlenecks in CPU, GPU, memory, or data transfer. Understanding these requirements will help direct your optimization efforts more effectively.
Profiling is a fundamental step in workload tuning. It allows you to gather detailed information about how your workload utilizes system resources, and where potential inefficiencies lie. Profiling tools can provide insights into both high-level and granular performance metrics. See Profiling tools.
High-level profiling tools#
For a broad overview, use tools like the PyTorch Profiler, which helps in understanding how PyTorch operations are executed and where time is spent. This is particularly useful for developers new to workload tuning, as it provides a comprehensive view without requiring in-depth knowledge of lower-level operations.
Kernel-level profiling tools#
When profiling indicates that GPUs are a performance bottleneck, delve deeper into kernel-level profiling. Tools such as the ROCr Debug Agent, ROCProfiler, and ROCm Compute Profiler offer detailed insights into GPU kernel execution. These tools can help isolate problematic GPU operations and provide data needed for targeted optimizations.
Analyze and tune#
Based on the insights gained from profiling, focus your tuning efforts on the identified bottlenecks. This might involve optimizing specific kernel operations, adjusting memory access patterns, or modifying computational algorithms.
The following subsections discuss optimization ranging from high-level and more automated strategies to more involved, hands-on optimization.
Optimize model inference with vLLM#
vLLM provides tools and techniques specifically designed for efficient model inference on AMD Instinct GPUs. See the official vLLM installation docs for installation guidance. Optimizing performance with vLLM involves configuring tensor parallelism, leveraging advanced features, and ensuring efficient execution.
Configuration for vLLM: Set engine arguments according to workload requirements.
Benchmarking and performance metrics: Measure latency and throughput to evaluate performance.
See also
See vLLM V1 performance optimization to learn more about vLLM performance optimization techniques.
Auto-tunable configurations#
Auto-tunable configurations can significantly streamline performance optimization by automatically adjusting parameters based on workload characteristics. For example:
PyTorch: Utilize PyTorch’s built-in auto-tuning features, such as the TunableOp module, which helps in optimizing operation performance by exploring different configurations.
MIOpen: Leverage MIOpen’s auto-tuning capabilities for convolutional operations and other primitives to find optimal settings for your specific hardware.
Triton: Use Triton’s auto-tuning features to explore various kernel configurations and select the best-performing ones.
Manual tuning#
Advanced developers can manually adjust parameters and configurations to optimize performance. Both Triton and HIP involve manual tuning aspects.
ROCm libraries: Optimize GPU performance by adjusting various parameters and configurations within ROCm libraries. This approach involves hands-on optimization to maximize efficiency for specific workloads.
Triton: Tune Triton kernels by adjusting parameters tailored to your workload to optimize GPU resource utilization and better leverage specific hardware features.
HIP: Profile and optimize HIP kernels by optimizing parallel execution, memory access patterns, and other aspects.
Iterate and validate#
Optimization is an iterative process. After applying tuning changes, re-profile the workload to validate improvements and ensure that the changes have had the desired effect. Continuous iteration helps refine the performance gains and address any new bottlenecks that may emerge.
ROCm provides a prebuilt optimized Docker image that has everything required to implement the LLM inference tips in this section. It includes ROCm, PyTorch, and vLLM. For more information, see vLLM inference.
Profiling tools#
AMD profiling tools provide valuable insights into how efficiently your application utilizes hardware and help diagnose potential bottlenecks that contribute to poor performance. Developers targeting AMD GPUs have multiple tools available depending on their specific profiling needs.
ROCProfiler tool collects kernel execution performance metrics. For more information, see the ROCProfiler documentation.
ROCm Compute Profiler builds upon ROCProfiler but provides more guided analysis. For more information, see ROCm Compute Profiler documentation.
Refer to Profiling and debugging to explore commonly used profiling tools and their usage patterns.
Once performance bottlenecks are identified, you can implement an informed workload tuning strategy. If kernels are the bottleneck, consider:
If auto-tuning does not meet your requirements, consider Triton kernel performance optimization.
If the issue is multi-GPU scale-out, try RCCL tuning and configuration.
This section discusses profiling and debugging tools and some of their common usage patterns with ROCm applications.
PyTorch Profiler#
PyTorch Profiler can be invoked inside Python scripts, letting you collect CPU and GPU performance metrics while the script is running. See the PyTorch Profiler tutorial for more information.
You can then visualize and view these metrics using an open-source profile visualization tool like Perfetto UI.
Use the following snippet to invoke PyTorch Profiler in your code.
import torch import torchvision.models as models from torch.profiler import profile, record_function, ProfilerActivity model = models.resnet18().cuda() inputs = torch.randn(2000, 3, 224, 224).cuda() with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof: with record_function("model_inference"): model(inputs) prof.export_chrome_trace("resnet18_profile.json")
Profile results in
resnet18_profile.jsoncan be viewed by the Perfetto visualization tool. Go to https://ui.perfetto.dev and import the file. In your Perfetto visualization, you’ll see that the upper section shows transactions denoting the CPU activities that launch GPU kernels while the lower section shows the actual GPU activities where it processes theresnet18inferences layer by layer.
Perfetto trace visualization example.#
ROCm profiling tools#
Heterogenous systems, where programs run on both CPUs and GPUs, introduce additional complexities. Understanding the critical path and kernel execution is all the more important. So, performance tuning is a necessary component in the benchmarking process.
With AMD’s profiling tools, developers are able to gain important insight into how efficiently their application is using hardware resources and effectively diagnose potential bottlenecks contributing to poor performance. Developers working with AMD Instinct GPUs have multiple tools depending on their specific profiling needs; these include:
ROCProfiler#
ROCProfiler is primarily a low-level API for accessing and extracting GPU hardware performance metrics, commonly called performance counters. These counters quantify the performance of the underlying architecture showcasing which pieces of the computational pipeline and memory hierarchy are being utilized.
Your ROCm installation contains a script or executable command called rocprof which provides the ability to list all
available hardware counters for your specific GPU, and run applications while collecting counters during
their execution.
This rocprof utility also depends on the ROCTracer and ROC-TX libraries, giving it the
ability to collect timeline traces of the GPU software stack as well as user-annotated code regions.
Note
rocprof is a CLI-only utility where inputs and outputs take the form of text and CSV files. These
formats provide a raw view of the data and puts the onus on the user to parse and analyze. rocprof
gives the user full access and control of raw performance profiling data, but requires extra effort to analyze the
collected data.
ROCm Compute Profiler#
ROCm Compute Profiler is a system performance profiler for high-performance computing (HPC) and machine learning (ML) workloads using Instinct GPUs. Under the hood, ROCm Compute Profiler uses ROCProfiler to collect hardware performance counters. The ROCm Compute Profiler tool performs system profiling based on all approved hardware counters for Instinct GPU architectures. It provides high level performance analysis features including System Speed-of-Light, IP block Speed-of-Light, Memory Chart Analysis, Roofline Analysis, Baseline Comparisons, and more.
ROCm Compute Profiler takes the guesswork out of profiling by removing the need to provide text input files with lists of counters to collect and analyze raw CSV output files as is the case with ROCProfiler. Instead, ROCm Compute Profiler automates the collection of all available hardware counters in one command and provides graphical interfaces to help users understand and analyze bottlenecks and stressors for their computational workloads on AMD Instinct GPUs.
Note
ROCm Compute Profiler collects hardware counters in multiple passes, and will therefore re-run the application during each pass to collect different sets of metrics.
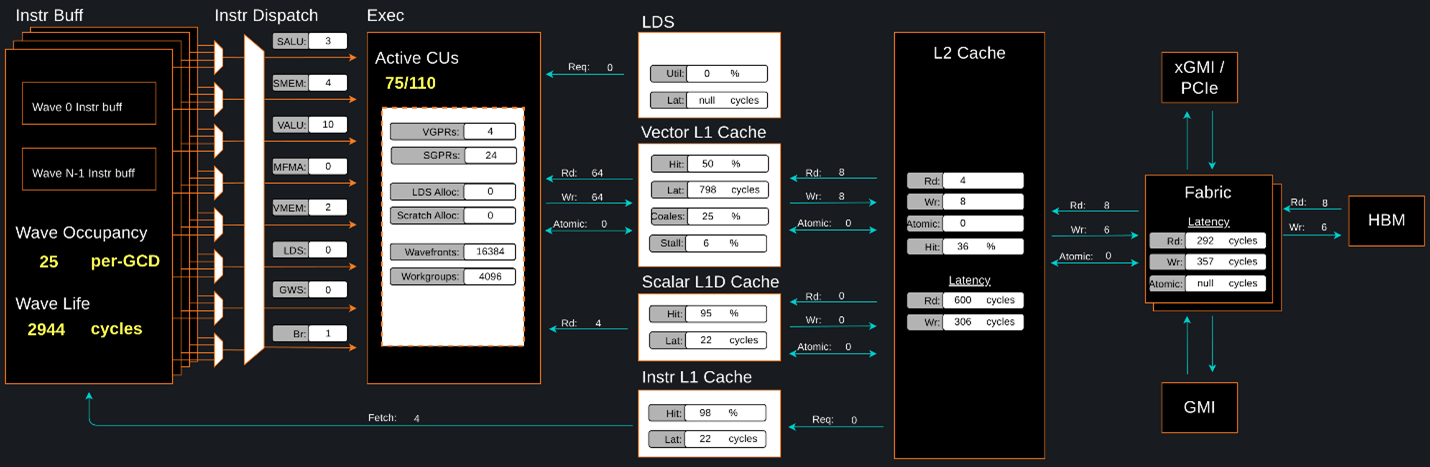
ROCm Compute Profiler memory chart analysis panel.#
In brief, ROCm Compute Profiler provides details about hardware activity for a particular GPU kernel. It also supports both a web-based GUI or command-line analyzer, depending on your preference.
ROCm Systems Profiler#
ROCm Systems Profiler is a comprehensive profiling and tracing tool for parallel applications, including HPC and ML packages, written in C, C++, Fortran, HIP, OpenCL, and Python which execute on the CPU or CPU and GPU. It is capable of gathering the performance information of functions through any combination of binary instrumentation, call-stack sampling, user-defined regions, and Python interpreter hooks.
ROCm Systems Profiler supports interactive visualization of comprehensive traces in the web browser in addition to high-level
summary profiles with mean/min/max/stddev statistics. Beyond runtime
information, ROCm Systems Profiler supports the collection of system-level metrics such as CPU frequency, GPU temperature, and GPU
utilization. Process and thread level metrics such as memory usage, page faults, context switches, and numerous other
hardware counters are also included.
Tip
When analyzing the performance of an application, it is best not to assume you know where the performance bottlenecks are and why they are happening. ROCm Systems Profiler is the ideal tool for characterizing where optimization would have the greatest impact on the end-to-end execution of the application and to discover what else is happening on the system during a performance bottleneck.
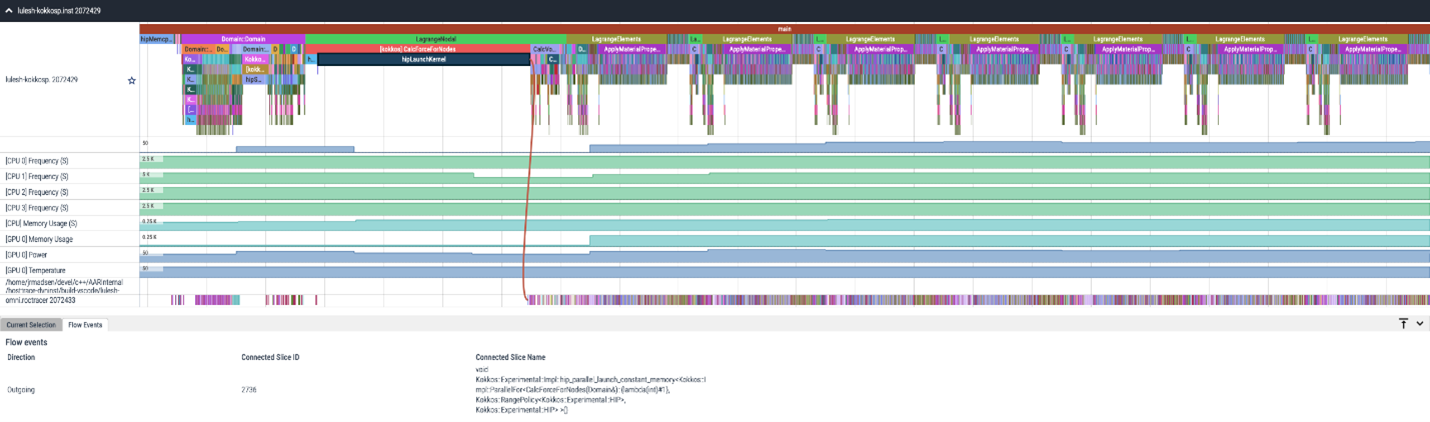
ROCm Systems Profiler timeline trace example.#
vLLM performance optimization#
vLLM is a high-throughput and memory efficient inference and serving engine for large language models that has gained traction in the AI community for its performance and ease of use. See vLLM V1 performance optimization, where you’ll learn how to:
Enable AITER (AI Tensor Engine for ROCm) to speed up on LLM models.
Configure environment variables for optimal HIP, RCCL, and Quick Reduce performance.
Select the right attention backend for your workload (AITER MHA/MLA vs. Triton).
Choose parallelism strategies (tensor, pipeline, data, expert) for multi-GPU deployments.
Apply quantization (
FP8/FP4) to reduce memory usage by 2-4× with minimal accuracy loss.Tune engine arguments (batch size, memory utilization, graph modes) for your use case.
Benchmark and scale across single-node and multi-node configurations.
PyTorch TunableOp#
TunableOp is a feature used to obtain the optimal GPU kernel for a key PyTorch operations. At the moment, TunableOp supports the tuning of dense matrix multiplies (GEMM, batched GEMM, GEMM and bias, and scaled GEMM). This feature is useful for squeezing out the last bit of performance. In short, it will try up to thousands of matrix multiply algorithms that are available in rocBLAS and hipBLASLt. A caveat is that as the math libraries improve over time, there is a less benefit to using TunableOp, and there is also no guarantee that the workload being tuned will be able to outperform the default GEMM algorithm in hipBLASLt.
Some additional references for PyTorch TunableOp include ROCm blog, TunableOp README, and llm tuning.
The three most important environment variables for controlling TunableOp are:
PYTORCH_TUNABLEOP_ENABLEDThe main on/off switch for all TunableOp implementations. Default is
0(disabled). Set to1to enable.PYTORCH_TUNABLEOP_TUNINGWhen enabled, if a tuned entry isn’t found, runs the tuning step and records the entry. Default is
1(enabled). Set to0to disable.PYTORCH_TUNABLEOP_VERBOSEEnables verbose output for debugging purposes – it can be useful to see if TunableOp is being used at all. Default is
0(disabled). Set to1to enable.
For the complete list of environment variables, see the TunableOp README. There are also Python APIs to set some of these environment variables, but the preferred way to set the TunableOp tuning parameters is to use the environment variables.
Workflow#
Use these environment variables to enable TunableOp for any applications or libraries that use PyTorch (2.3 or later).
The first step is the tuning pass:
Enable TunableOp and tuning. Optionally enable verbose mode:
PYTORCH_TUNABLEOP_ENABLED=1 PYTORCH_TUNABLEOP_VERBOSE=1 your_script.sh
This pass can be very slow. The output will be the
tunableop_results.csvfile containing a list of GEMMs encountered and the optimal GPU kernel that was identified.Multi-GPU tuning is supported, producing a separate tunableop_results.csv file for each GPU. The tuning algorithm executes independently on each GPU, with each tuning process sandboxed to its respective GPU. There is no inter-GPU communication during tuning.
For data-parallel algorithms, where GEMM configurations across GPUs are typically identical, this approach can result in redundant work. In such cases, running the workload on a single GPU might suffice. However, for algorithms involving multiple levels of parallelism (as in data parallelism combined with ML model parallelism), different GPUs might require distinct GEMM parameters. In these scenarios, a multi-GPU configuration is recommended.
In the second step, we re-run the workload with optimal configuration using the tunableop_results.csv file obtained in step 1.
Enable TunableOp, disable tuning, and measure:
PYTORCH_TUNABLEOP_ENABLED=1 PYTORCH_TUNABLEOP_TUNING=0 your_script.sh
Compare the wall-clock time from this second step to your reference wall-clock time with TunableOp completely disabled (PYTORCH_TUNABLEOP_ENABLED=0).
Offline tuning#
A new feature of TunableOp, offline tuning, is available in upstream PyTorch and supported in PyTorch 2.6 or later.
Traditionally, tuning is performed in-place during workload execution. While convenient for one-off tuning, this approach can become cumbersome if frequent re-tuning is required – such as when a new version of a math library is released. In these cases, re-running the workload and performing tuning repeatedly can be inefficient.
Offline tuning addresses this challenge by decoupling the tuning process from workload execution. It enables the collection of GEMMs from a workload during a collection pass, followed by tuning these GEMMs in a separate tuning pass, without re-running the original workload. This approach significantly reduces compute resource requirements, particularly for time-intensive workloads.
For workflow instructions, refer to the Offline Tuning documentation.
PyTorch inductor max-autotune tuning knobs#
The following are suggestions for optimizing matrix multiplication (GEMM) and
convolution (conv) operations in PyTorch using inductor, a part of the
PyTorch compilation framework.
Learn more about TorchInductor environment variables and usage in the PyTorch documentation.
Note
Experimental: TunableOp (see the PyTorch TunableOp section) can also be used in combination
with TorchInductor max-autotune mode to boost ATen GEMM performance but will further increase tuning time.
The environment variable TORCHINDUCTOR_AUTOTUNE_MULTI_DEVICE=1 can be useful in single GPU workloads to distribute Triton GEMM tuning.
Triton backend#
The goal is to leverage Triton to achieve better performance. To tune Triton kernels with gemm and convolution ops (conv), use the
torch.compile function with the max-autotune mode. This benchmarks a
predefined list of Triton configurations and selects the fastest one for each
shape. See the configurations in PyTorch source code:
This tuning will select the best Triton gemm configurations according to tile-size
(BLOCK_M, BLOCK_N, BLOCK_K), num_stages, num_warps and mfma instruction size ( matrix_instr_nonkdim )
(see “Triton kernel optimization” section for more details).
Set
torch._inductor.config.max_autotune = TrueorTORCHINDUCTOR_MAX_AUTOTUNE=1.Or, for more fine-grained control:
torch._inductor.config.max_autotune_gemm = TrueTo enable tuning or lowering of
mm/convs.torch._inductor.config.max_autotune.pointwise = TrueTo enable tuning for
pointwise/reductionops.torch._inductor.max_autotune_gemm_backendsorTORCHINDUCTOR_MAX_AUTOTUNE_GEMM_BACKENDSSelects the candidate backends for
mmauto-tuning. Defaults toTRITON,ATEN. Limiting this toTRITONmight improve performance by enabling more fusedmmkernels instead of going to rocBLAS.
Inference can see large improvements on AMD GPUs by utilizing
torch._inductor.config.freezing=Trueor theTORCHINDUCTOR_FREEZING=1variable, which in-lines weights as constants and enables constant folding optimizations.Enabling
inductor’s cpp_wrapper might improve overhead. This generates C++ code which launches Triton binaries directly withhipModuleLaunchKerneland relies on hipification.torch._inductor.config.cpp_wrapper=TrueorTORCHINDUCTOR_CPP_WRAPPER=1Convolution workloads might see a performance benefit by specifying
torch._inductor.config.layout_optimization=TrueorTORCHINDUCTOR_LAYOUT_OPTIMIZATION=1. This can help performance by enforcingchannel_lastmemory format on the convolution in TorchInductor, avoiding any unnecessary transpose operations. Note thatPYTORCH_MIOPEN_SUGGEST_NHWC=1is recommended if using this.To extract the Triton kernels generated by
inductor, set the environment variableTORCH_COMPILE_DEBUG=1, which will create atorch_compile_debug/directory in the current path. The wrapper codes generated byinductorare in one or moreoutput_code.pyfiles corresponding to the FX graphs associated with the model. The Triton kernels are defined in these generated codes.
Composable Kernel backend#
You can enable the Composable Kernel (CK) backend by appending CK to the comma-separated list of backends. This allows the
auto-tuning process to use kernels from the Composable Kernel library.
torch._inductor.max_autotune_gemm_backends or TORCHINDUCTOR_MAX_AUTOTUNE_GEMM_BACKENDS.
Install the Composable Kernel library’s Python wrapper via pip using the following command:
pip install git+https://github.com/rocm/composable_kernel@develop
This wrapper library is responsible for constructing a list of kernel instances available in the Composable Kernel library,
as well as storing the kernel instance C++ includes in a known location (so clang can look into these paths when compiling the gemm auto-tune candidates).
matmul(withfloat16andbfloat16inputs, row-major X, row-major or column-major W)
addmm(withfloat16orbfloat16X, W and Bias; row-major X, row-major or column-major W; Bias can be broadcast either along row-major or column-major dimension)
scaled_mm(float8_e4m3fnuzinputs,bfloat16output)
conv2d(withfloat32,float16orbfloat16inputs, channels-last weight layout)
For working examples, see test/inductor/test_ck_backend.py.
Compiling or build time can be configured by modifying
torch._inductor.configto reduce the build time to avoid time-out.compile_threads: Number of threads used for compilation. Set it to the number of available CPU cores.rocm.n_max_profiling_configs: Limiting the number of kernels to speed up compilation.
Setting environment variable
PYTORCH_MIOPEN_SUGGEST_NHWC=1to optimize convolution operations.
Debugging and troubleshooting performance:
Generate a standalone executable runner to debug or assess kernels’ performance by setting environment variable
INDUCTOR_CK_BACKEND_GENERATE_TEST_RUNNER_CODE=1to facilitate debugging and profiling. By default, the CK backend will not build a standalone executable runner.Enable debug by passing compilation flags (e.g.,
is_debug) to clang when compiling the kernels intorch._inductor.config.rocmclass.The generated source files and other products of clang compilation are located in the torch inductor root directory (default:
/tmp/torchinductor_root)
ROCm library tuning#
ROCm library tuning involves optimizing the performance of routine computational
operations (such as GEMM) provided by ROCm libraries like
hipBLASLt, Composable Kernel,
MIOpen, and RCCL. This tuning aims
to maximize efficiency and throughput on Instinct MI300X GPUs to gain
improved application performance.
GEMM (general matrix multiplication)#
GEMMs (General Matrix Multiplications) are a fundamental building block for many operations in neural networks.
GEMM is defined as C = αAB + βC where A is an MxK matrix input and B is KxN matrix input,
and C is MxN matrix input and is overwritten by the output. α and β are scalar inputs.
hipBLASLt is a library that provides general matrix-matrix operations with a flexible API
and extends functionalities beyond a traditional BLAS library.
hipBLASLt benchmarking#
The GEMM library hipBLASLt provides a benchmark tool for its supported operations. Refer to the documentation for details.
Example 1: Benchmark mix fp8 GEMM
HIP_FORCE_DEV_KERNARG=1 hipblaslt-bench --alpha 1 --beta 0 -r f16_r \ --a_type f16_r --b_type f8_r --compute_type f32_f16_r \ --initialization trig_float --cold_iters 100 --iters 1000 --rotating 256
Example 2: Benchmark forward epilogues and backward epilogues
HIPBLASLT_EPILOGUE_RELU: "--activation_type relu";HIPBLASLT_EPILOGUE_BIAS: "--bias_vector";HIPBLASLT_EPILOGUE_RELU_BIAS: "--activation_type relu --bias_vector";HIPBLASLT_EPILOGUE_GELU: "--activation_type gelu";HIPBLASLT_EPILOGUE_DGELU": --activation_type gelu --gradient";HIPBLASLT_EPILOGUE_GELU_BIAS: "--activation_type gelu --bias_vector";HIPBLASLT_EPILOGUE_GELU_AUX: "--activation_type gelu --use_e";HIPBLASLT_EPILOGUE_GELU_AUX_BIAS: "--activation_type gelu --bias_vector --use_e";HIPBLASLT_EPILOGUE_DGELU_BGRAD: "--activation_type gelu --bias_vector --gradient";HIPBLASLT_EPILOGUE_BGRADA: "--bias_vector --gradient --bias_source a";HIPBLASLT_EPILOGUE_BGRADB: "--bias_vector --gradient --bias_source b";
hipBLASLt auto-tuning using hipblaslt-bench#
Use the auto-tuning tool in hipBLASLt to get the best solution for a given problem size.
Prerequisite#
Build hipBLASLt. See the hipBLASLt repository to see detailed build instructions.
Quick start#
Create a working folder for the auto-tuning tool, for example, tuning/.
Set the
ProblemType,TestConfig, andTuningParametersin the YAML file. You can modify the template YAML file inhipblaslt/utilities.
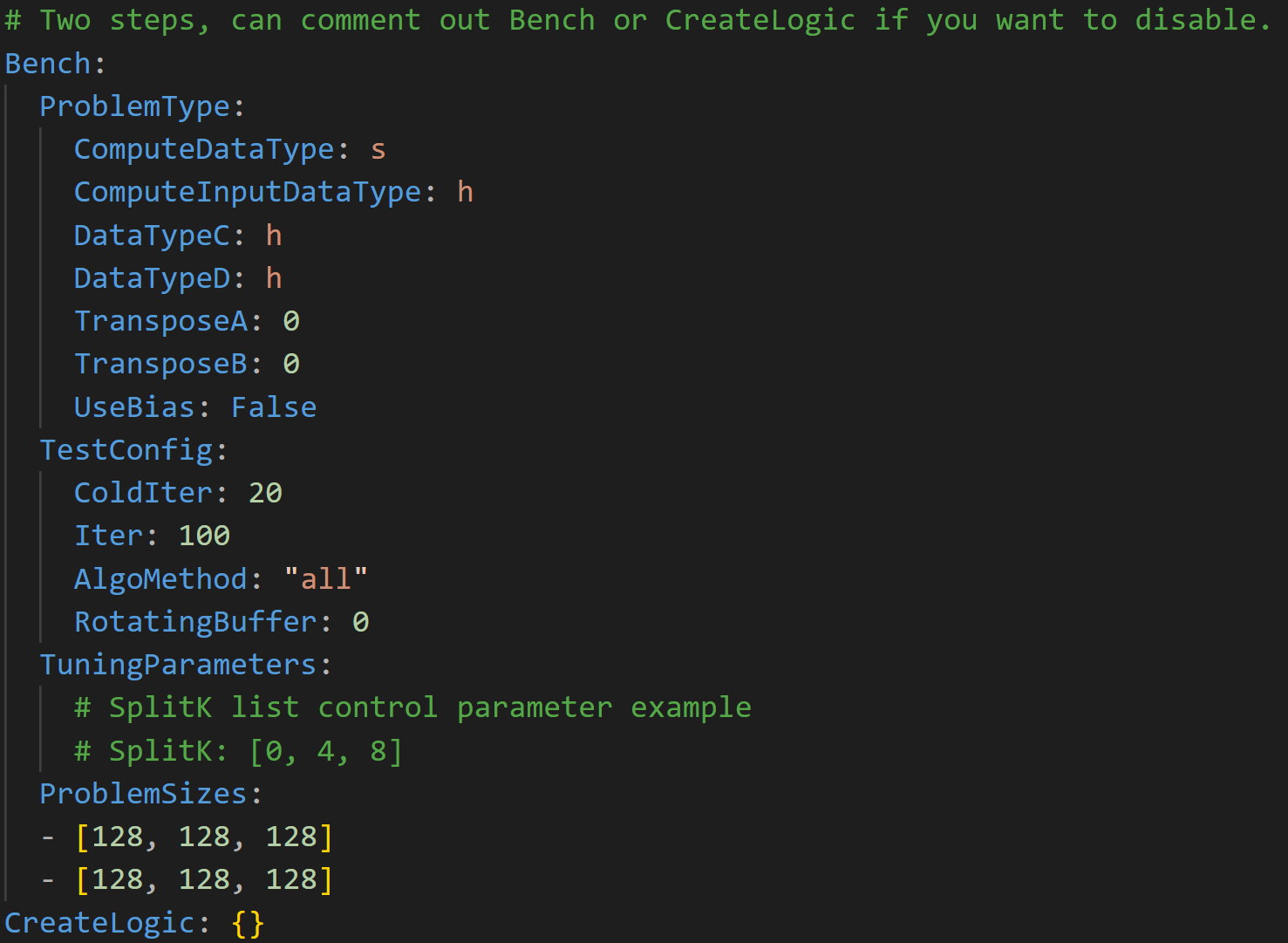
Run the following command to start tuning.
# python3 hipblaslt/utilities/find_exact.py <path-to-config-yaml> <path-to-the-root-of-built-hipblaslt> <working-directory> # Assume we're in folder tuning, the default root of the build folder of hipblaslt is hipblaslt/build/release python3 ../hipblaslt/utilities/find_exact.py tuning.yaml hipblaslt/build/release ./
Output#
The tool will create two output folders. The first one is the benchmark results,
the second one is the generated equality kernels. If SplitK is used, the solution’s GlobalSplitU will
also change if the winner is using a different SplitK from the solution. The YAML files generated inside the
folder 1_LogicYaml are logic ones. These YAML files are just like those generated from TensileLite.
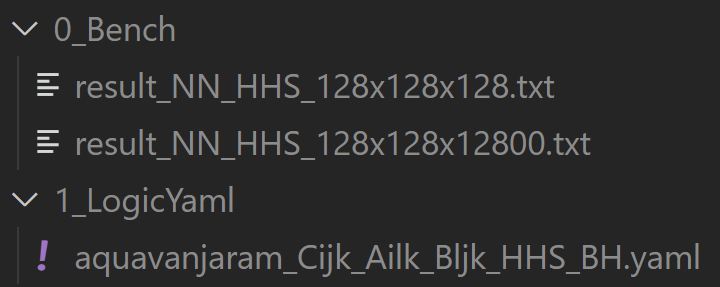
A quick view of the config YAML#
The tuning tool is a two-step tool. It first runs the benchmark, then it creates the equality YAML for the user. Note that this config YAML file is different from the config YAML used in TensileLite.
Benchmarking
The first step is to run the benchmark,
find_exact.pywill run the benchmark withhipblaslt-bench. For the default configurations, see the Python file.defaultBenchOptions = {"ProblemType": { "TransposeA": 0, "TransposeB": 0, "ComputeInputDataType": "s", "ComputeDataType": "s", "DataTypeC": "s", "DataTypeD": "s", "UseBias": False }, "TestConfig": { "ColdIter": 20, "Iter": 100, "AlgoMethod": "all", "RequestedSolutions": 2, # Only works in AlgoMethod heuristic "SolutionIndex": None, # Only works in AlgoMethod index "ApiMethod": "cpp", "RotatingBuffer": 0, }, "TuningParameters": { "SplitK": [0] }, "ProblemSizes": []} defaultCreateLogicOptions = {} # Currently unused
TestConfigColdIter: This is number the warm-up iterations before starting the kernel benchmark.Iter: This is the number of iterations in kernel benchmarkingAlgoMethod: We recommended to keep this unchanged because method “all” returns all the available solutions for the problem type.ApiMethod: We have c, mix, and cpp. Doesn’t affect the result much.RotatingBuffer: This is a size in the unit of MB. Recommended to set the value equal to the size of the cache of the card to avoid the kernel fetching data from the cache.
TuningParametersSplitK: DivideKintoNportions. Not every solution supportsSplitK. The solution will be skipped if not supported.
CreateLogicCurrently no control parameters.
hipBLASLt backend assembly generator tuning#
hipBLASLt has a backend assembly generator in hipBLASLt’s GitHub repository, named TensileLite. TensileLite enables performance optimization by tuning the backend assembly generator. The following section explains how to use TensileLite to tune hipBLASLt for better performance.
cd /hipBLASLt/tensilelite
./Tensile/bin/Tensile config.yaml output_path
config.yaml#
This file contains the parameters and settings for the tuning process. Here’s a breakdown of the important sections:
GlobalParametersThe set of parameters which provides context for the entire tuning exercise.
Using
0forNumElementsToValidateis suggested for performance tuning to avoid validation overhead.globalParameters["NumElementsToValidate"] = 0
BenchmarkProblemsDefines the set of kernel specifications as well as the size definitions for the tuning exercise.
ProblemType(OperationType,DataType,TransposeA,TransposeB)BenchmarkCommonParameters(the same parameters for all solutions)ForkParametersBenchmarkFinalParameters(ProblemSizes)
LibraryLogicSpecifies the target environment and platform.
ScheduleNamealdebaranis MI200aquavanjaramis MI300
$ ls aldebaran aquavanjaram navi31 navi32
LibraryLogic: ScheduleName: "aldebaran" DeviceNames: [Device 0050, Device 0052, Device 0054, Device 0062, Device 7400] ArchitectureName: "gfx90a"
LibraryClientIf defined, this will enable step 4 of the tuning process, which means the final library will be created.
$ ls aldebaran_Cijk_Ailk_Bjlk_S.yaml
TensileLite tuning flow#
The TensileLite tuning flow consists of seven steps. In the first six steps, the programmable benchmarking protocol generates fast kernel candidates. In the final step (step 7), these candidates are benchmarked against a predefined set of problem sizes.
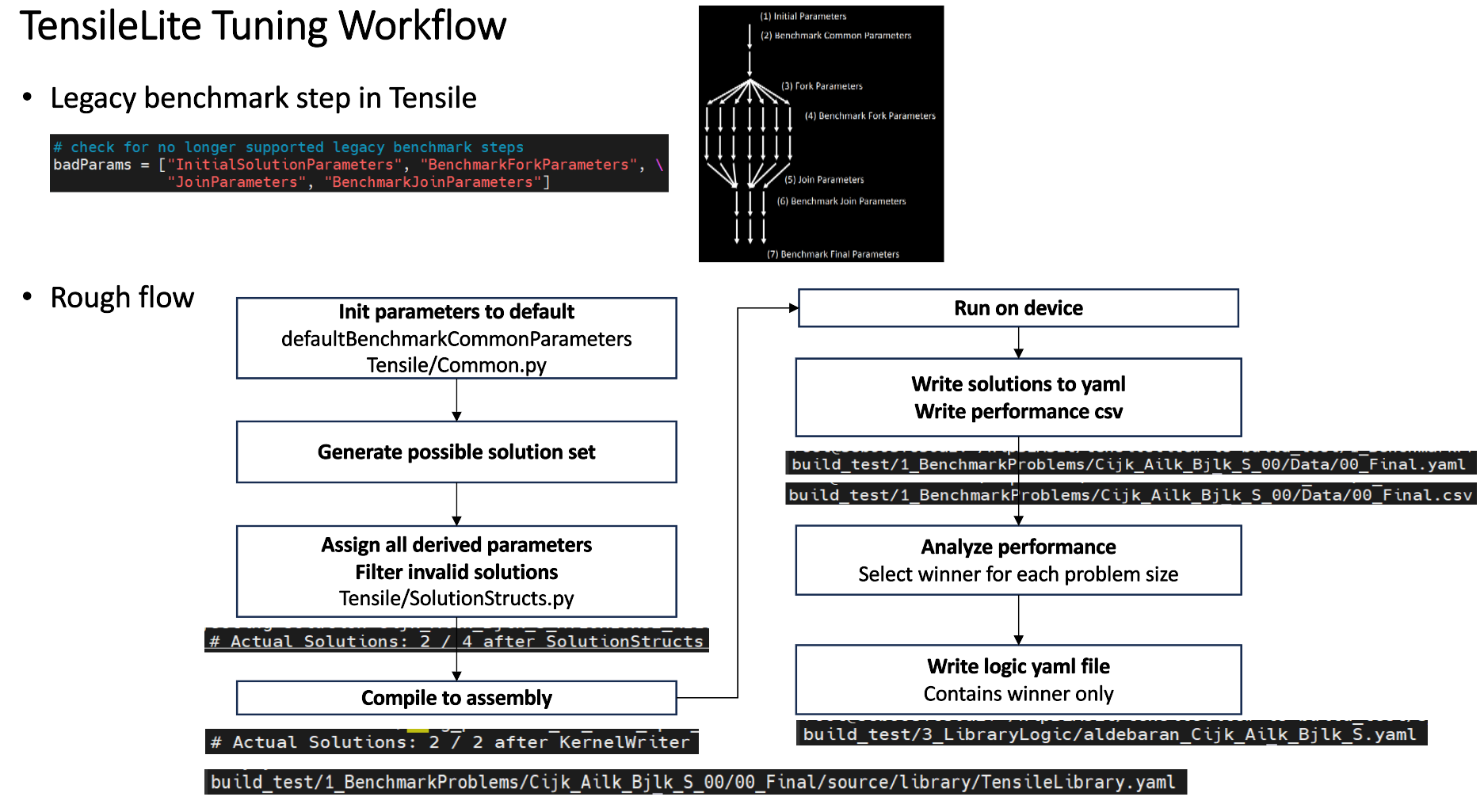
Step 1: Initial solution parameters#
Before Tensile is able to benchmark a kernel parameter in Step 2 of the preceding figure,
such as PrefetchGlobalRead={False, True}, all other kernel parameters not being measured must be specified.
Therefore, the first step is to initialize a list of default kernel parameters, then subsequent steps of
benchmarking will override a parameter from this default list, with the parameter determined from benchmarking.
Tensile is pre-loaded with default parameters for any unspecified during tuning.
Step 2: Benchmark common parameters#
Benchmarking common parameters determines parameters which are universally preferable to their alternatives regardless of other parameters. To benchmark common parameters:
User specifies parameters and values to benchmark.
Tensile benchmarks all parameter combinations for a user-specified problem size.
Tensile selects the fastest parameter combination which is now labeled determined and will subsequently be used.
In practice, these parameters are not used, since globally preferred parameters are set as defaults in Tensile and do not need to be re-measured.
Step 3: Fork parameters#
Rather than continuing to determine globally fastest parameters, which eventually leads to a single fastest kernel, forking creates many different kernels, all of which will be considered for use. All forked parameters are considered determined, i.e., they aren’t measured to determine which is fastest. The preceding figure shows 7 kernels being forked in Step 3.
Step 4: Benchmark fork parameters#
Next, tuning continues its refinement by determining fastest parameters for each forked permutation, same as in Step 2.
Step 5: Join parameters#
After tuning the forked kernels, joining reduces the list of kernels so that fewer kernels
will be considered for final use. Each kernel in the resulting list must have different values
for the listed JoinParameters, for example, employing JoinParameters = MacroTile will result in only a
few final kernels, each with a different MacroTile. If there are multiple kernels with the same MacroTile,
only the fastest is kept. In the above figure the 7 forked kernel have been reduced to 3 joined kernels.
Step 6: Benchmark join parameters#
Users can further tune parameters of the joined kernels. This steps is same as Steps 4 except that it tunes after joining so that there are fewer kernels to be tuned. In practice, this step is not used; using Step 4 is preferred so that all parameters are measured before joining.
Step 7: Benchmark final parameters#
At the conclusion of Step 6, all parameters of all kernels have been determined and the final set of kernels for consideration has been established. Now all final kernels will be measured against all problem sizes specified by the user. Problem sizes can be specified as Range sizes and Exact sizes. Range sizes cause benchmarking of a broad range of sizes, and Tensile will be able to interpolate which kernel is best even between the specifically measured sizes. Exact sizes cause a single problem size to be measured, and the final library is guaranteed to choose the fastest kernel for that size. This final benchmarking generates the data that is subsequently analyzed for creating the mapping of problem size to optimal kernel.
Update logic YAML files#
The logic YAML files in hipBLASLt are located in
library/src/amd_detail/rocblaslt/src/Tensile/Logic/asm_full/.
To merge the YAML files from the tuned results in TensileLite, use the
merge.py located in tensilelite/Tensile/Utilities with the following
command:
merge.py original_dir new_tuned_yaml_dir output_dir
The following table describes the logic YAML files.
Logic YAML |
Description |
|---|---|
|
Update the equality file when your tuned YAML is an exact tuning. |
|
Update the gridbased file when your tuned YAML is a grid-based tuning. |
|
Update the freesize file when your tuned YAML contains confidential sizes, or others. Note that freesize YAML files do not require any problem size. |
Tensile optimization and performance tuning tips#
- MI16x16 versus MI32x32
MI16x16 outperforms MI32x32 due to its superior power efficiency. The MI16x16 format refers to the
v_mfmainstruction (such asv_mfma_f32_16x16x16f16). See https://llvm.org/docs/AMDGPU/AMDGPUAsmGFX940.html#vop3p.- Clock differences among XCDs
There can be a clock speed variation of 3% to 10% among different XCDs. Typically, XCD0 has the highest clock speed, while XCD7 has the lowest on MI300X. For optimal efficiency calculations on MI300X, use the XCD with the lowest average clock speed. If the average clock speed of XCD0 is used, target efficiencies (such as, 95% for DGEMM HPL cases with K=512) may not be achievable.
- WorkGroupMapping
To maximize L2 cache efficiency, use multiples of the XCD number. For MI300X, this means using multiples of 8 (such as, 24, 32, 40).
- GEMM stride issues
On MI300, if the matrix stride in GEMM is a multiple of 512 bytes, it can lead to Tagram channel hotspotting issues, causing a significant performance drop, especially for TN transpose cases. This can increase the latency of VMEM instructions and cause a notable performance drop. To avoid this, use stride padding to ensure the stride is not a multiple of 512 bytes (for instance, for TN F16 GEMM, set
lda = ldb = K + 128whenK % 256 == 0).
Optimizing Composable Kernel GEMM kernels#
The performance of a GEMM kernel is significantly influenced by the input values. The performance hierarchy based on input value types, from highest to lowest, is as follows:
Case 1: [all 0]
Case 2: [all identical integers]
Case 3: [random integers]
Case 4: [random floats]
There can be more than a 20 percent performance drop between Case 1 and Case 4, and a 10 percent drop between random integers and random floats.
Additionally, bf16 matrix core execution is noticeably faster than f16.
Distributing workgroups with data sharing on the same XCD can enhance performance (reduce latency) and improve benchmarking stability.
CK provides a rich set of template parameters for generating flexible accelerated computing kernels for difference application scenarios.
See Optimizing with Composable Kernel for an overview of Composable Kernel GEMM kernels, information on tunable parameters, and examples.
MIOpen#
MIOpen is AMD’s open-source, deep learning primitives library for GPUs. It implements fusion to optimize for memory bandwidth and GPU launch overheads, providing an auto-tuning infrastructure to overcome the large design space of problem configurations.
Convolution#
Many of MIOpen kernels have parameters which affect
their performance. Setting these kernel parameters to optimal values
for a given convolution problem, allows reaching the best possible
throughput. The optimal values of these kernel parameters are saved
in PerfDb (Performance database). PerfDb is populated through
tuning. To manipulate the tuning level, use the environment variable
MIOPEN_FIND_ENFORCE (1-6). Optimal values of kernel parameters are
used to benchmark all applicable convolution kernels for the given
convolution problem. These values reside in the FindDb. To manipulate
how to find the best performing kernel for a given convolution
problem, use the environment variable MIOPEN_FIND_MODE (1-5).
Tuning in MIOpen#
MIOPEN_FIND_ENFORCE=DB_UPDATE,2Performs auto-tuning and update to the PerfDb.
MIOPEN_FIND_ENFORCE=SEARCH,3Only perform auto-tuning if PerfDb does not contain optimized value for a given convolution problem
What does PerfDb look like?
[
2x128x56xNHWCxF, [
ConvAsm1x1U : 1,8,2,64,2,4,1,8 ; // optimum kernel params for convolution problem 2x128x56xNHWCxF
ConvOclDirectFwd1x1 : 1,128,1,1,0,2,32,4,0; // optimum kernel params for convolution problem 2x128x56xNHWCxF
],
2x992x516xNHWCxF, [
ConvAsm1x1U : 64,18,2,64,2,4,41,6 ; // optimum kernel params for convolution problem 2x992x516xNHWCxF
ConvOclDirectFwd1x1 : 54,128,21,21,1,23,32,4,0 // optimum kernel params for convolution problem 2x992x516xNHWCxF
]
...
]
See Using the performance database for more information.
Finding the fastest kernel#
MIOPEN_FIND_MODE=NORMAL,1Benchmark all the solvers and return a list (front element is the fastest kernel).
MIOPEN_FIND_MODE=FAST,2Check FindDb (Find database) if convolution problem is found return - else immediate fallback mode (predict the performing kernel parameters based on mathematical and AI models).
MIOPEN_FIND_MODE=HYBRID,3Check FindDb if convolution problem is found return - else benchmark that problem.
What does FindDb look like?
[
2x128x56xNHWCxF, [
ConvAsm1x1U : 0.045 (time), 12312 (workspace), algo_type;
ConvOclDirectFwd1x1 : 1.145 (time), 0 (workspace), algo_type;
],
2x992x516xNHWCxF, [
ConvAsm1x1U : 2.045 (time), 12312 (workspace), algo_type;
ConvOclDirectFwd1x1 : 1.145 (time), 0 (workspace), algo_type;
]
...
]
See Using the find APIs and immediate mode for more information.
For example:
MIOPEN_FIND_ENFORCE=3 MIOPEN_FIND_MODE=1 ./bin/MIOpenDriver convbfp16 -n 1 -c 1024 -H 14 -W 14 -k 256 -y 1 -x 1 -p 0 -q 0 -u 1 -v 1 -l 1 -j 1 -m conv -g 1 -F 1
RCCL#
RCCL is a stand-alone library of standard collective communication routines for GPUs, implementing all-reduce, all-gather, reduce, broadcast, reduce-scatter, gather, scatter, and all-to-all. RCCL supports an arbitrary number of GPUs installed in a single node or multiple nodes and can be used in either single- or multi-process (such as MPI) applications.
The following subtopics include information on RCCL features and optimization strategies:
Use all eight GPUs#
In an MI300X architecture, there are dedicated links between each pair of GPUs in a fully connected topology. Therefore, for collective operations, the best performance is achieved when all 8 GPUs and, hence, all the links between them are used. In the case of 2- or 4-GPU collective operations (generally less than 8 GPUs), you can only use a fraction of the potential bandwidth on the node.
The following figure shows an MI300X node-level architecture of a system with AMD EPYC processors in a dual-socket configuration and eight AMD Instinct MI300X GPUs. The MI300X OAMs attach to the host system via PCIe Gen 5 x16 links (yellow lines). The GPUs use seven high-bandwidth, low-latency AMD Infinity Fabric™ links (red lines) to form a fully connected 8-GPU system.
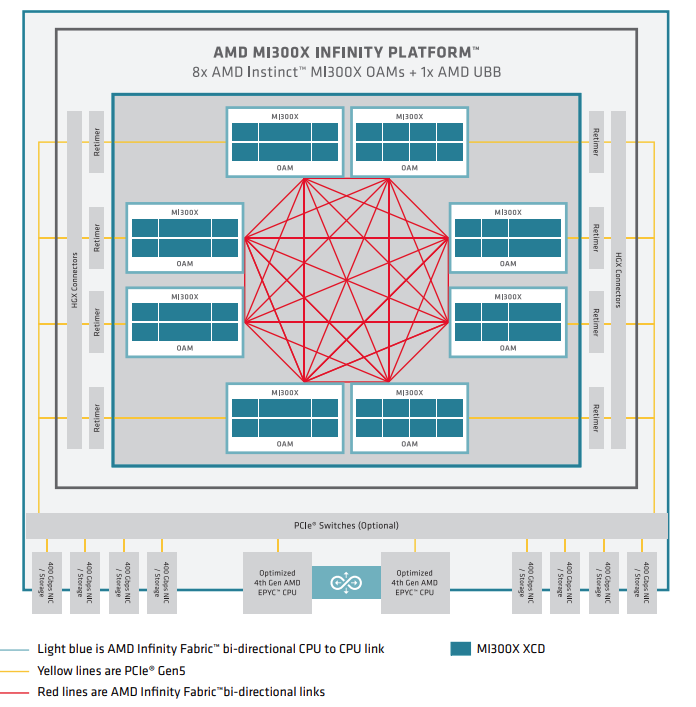
MI300 Series node-level architecture showing 8 fully interconnected MI300X OAM modules connected to (optional) PCIe switches via re-timers and HGX connectors.#
Disable NUMA auto-balancing#
In order to reduce performance variability and also achieve better performance, you need to make sure that NUMA auto-balancing is disabled on the node.
Check whether NUMA auto-balancing is disabled, by running the
following command: cat /proc/sys/kernel/numa_balancing and
checking whether the output is 0.
If the output is 1, you can disable NUMA auto-balancing by running the
following command: sudo sysctl kernel.numa_balancing=0. For more details,
see AMD Instinct MI300X system optimization.
Disable ACS for multi-node RCCL#
Check if ACS is disabled with sudo lspci -vvv \| grep -i "acsctl".
This will print many lines. Check if there are any that show SrcValid+
If there are any SrcValid+, then use the following disable_acs.sh script
to disable ACS (requires sudo).
#!/bin/bash
#
# Disable ACS on every device that supports it
#
PLATFORM=$(dmidecode --string system-product-name)
logger "PLATFORM=${PLATFORM}"
# Enforce platform check here.
#case "${PLATFORM}" in
#"OAM"*)
#logger "INFO: Disabling ACS is no longer necessary for ${PLATFORM}"
#exit 0
#;;
#*)
#;;
#esac
# must be root to access extended PCI config space
if [ "$EUID" -ne 0 ]; then
echo "ERROR: $0 must be run as root"
exit 1
fi
for BDF in \`lspci -d "*:*:*" \| awk '{print $1}'`; do
# skip if it doesn't support ACS
setpci -v -s ${BDF} ECAP_ACS+0x6.w > /dev/null 2>&1
if [ $? -ne 0 ]; then
#echo "${BDF} does not support ACS, skipping"
continue
fi
logger "Disabling ACS on \`lspci -s ${BDF}`"
setpci -v -s ${BDF} ECAP_ACS+0x6.w=0000
if [ $? -ne 0 ]; then
logger "Error enabling directTrans ACS on ${BDF}"
continue
fi
NEW_VAL=`setpci -v -s ${BDF} ECAP_ACS+0x6.w \| awk '{print $NF}'\`
if [ "${NEW_VAL}" != "0000" ]; then
logger "Failed to enabling directTrans ACS on ${BDF}"
continue
fi
done
exit 0
Run RCCL-Unittests#
In order to verify RCCL installation and test whether all parts and units of RCCL work as expected you can run the RCCL-Unittests which is explained in ROCm/rccl.
NPKit profiler#
To collect fine-grained trace events in RCCL components, especially in giant collective GPU kernels you can use the NPKit profiler explained in ROCm/rccl.
RCCL-tests#
RCCL-tests are performance and error-checking tests for RCCL maintained in ROCm/rccl-tests.
These tests are one of the best ways to check the performance of different collectives provided by RCCL. You can select collectives, message sizes, datatypes, operations, number of iterations, etc., for your test, and then rccl-tests deliver performance metrics such as latency, algorithm bandwidth, and bus bandwidth for each case.
Use one-process-per-GPU mode#
RCCL delivers the best performance for collectives when it is configured in a one-process-per-GPU mode. This is due to the fact that for a one-process-per-multiple-GPUs configuration, you can run into kernel launch latency issues. This is because ROCm serializes kernel launches on multiple GPUs from one process which hurts performance.
RCCL in E2E workloads#
Use the following environment variable to increase the number of channels used by RCCL when using RCCL in end-to-end workloads to potentially improve the performance:
export NCCL_MIN_NCHANNELS=112
Triton kernel performance optimization#
Triton kernel optimization encompasses a variety of strategies aimed at maximizing the efficiency and performance of GPU computations. These strategies include optimizing overall GPU resource utilization, tuning kernel configurations, and leveraging specific hardware features to achieve higher throughput and lower latency.
Auto-tunable kernel configurations#
Auto-tunable kernel configuration involves adjusting memory access and computational resources assigned to each compute unit. It encompasses the usage of LDS, register, and task scheduling on a compute unit.
The GPU contains global memory, local data share (LDS), and registers. Global memory has high access latency, but is large. LDS access has much lower latency, but is smaller. It is a fast on-CU software-managed memory that can be used to efficiently share data between all work items in a block. Register access is the fastest yet smallest among the three.
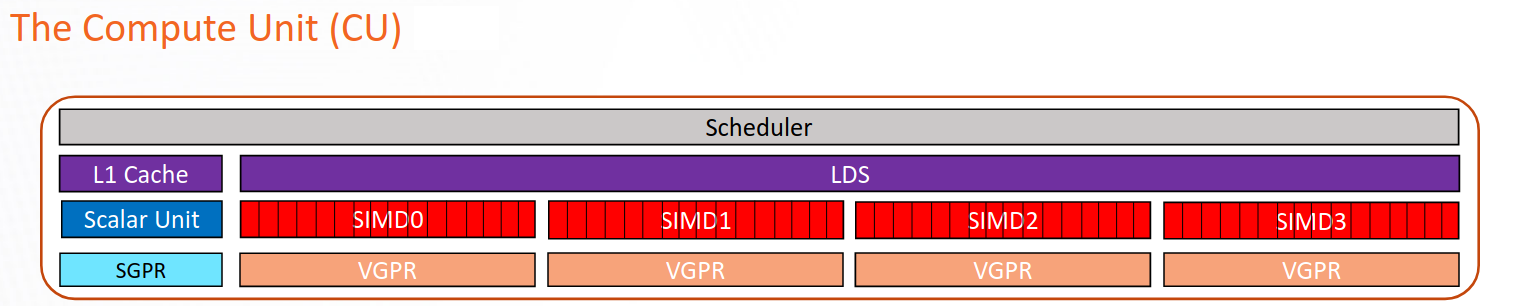
Schematic representation of a CU in the CDNA2 or CDNA3 architecture.#
The following is a list of kernel arguments used for tuning performance and resource allocation on AMD GPUs, which helps in optimizing the efficiency and throughput of various computational kernels.
num_stages=nAdjusts the number of pipeline stages for different types of kernels. On AMD GPUs, set
num_stagesaccording to the following rules:For kernels with a single GEMM, set to
2.For kernels with two GEMMs fused (Flash Attention, or any other kernel that fuses 2 GEMMs), set to
1.For kernels that fuse a single GEMM with another non-GEMM operator (for example ReLU activation), set to
2.For kernels that have no GEMMs, set to
1.
waves_per_eu=nHelps to manage Vector General Purpose Registers (VGPR) usage to achieve desired occupancy levels. This argument hints to the compiler to reduce VGPR to achieve
noccupancy wherenis a number. The goal is to achieve a certain occupancy level for each Execution Unit (EU, also called SIMD Unit) to achieve better latency or throughput. For more information on how to compute occupancy, see Compute the occupancy of a kernel.This argument is useful if:
The occupancy of the kernel is limited by VGPR usage, and
The current VGPR usage is only a few above a boundary in Occupancy related to VGPR usage in an Instinct MI300X GPU.
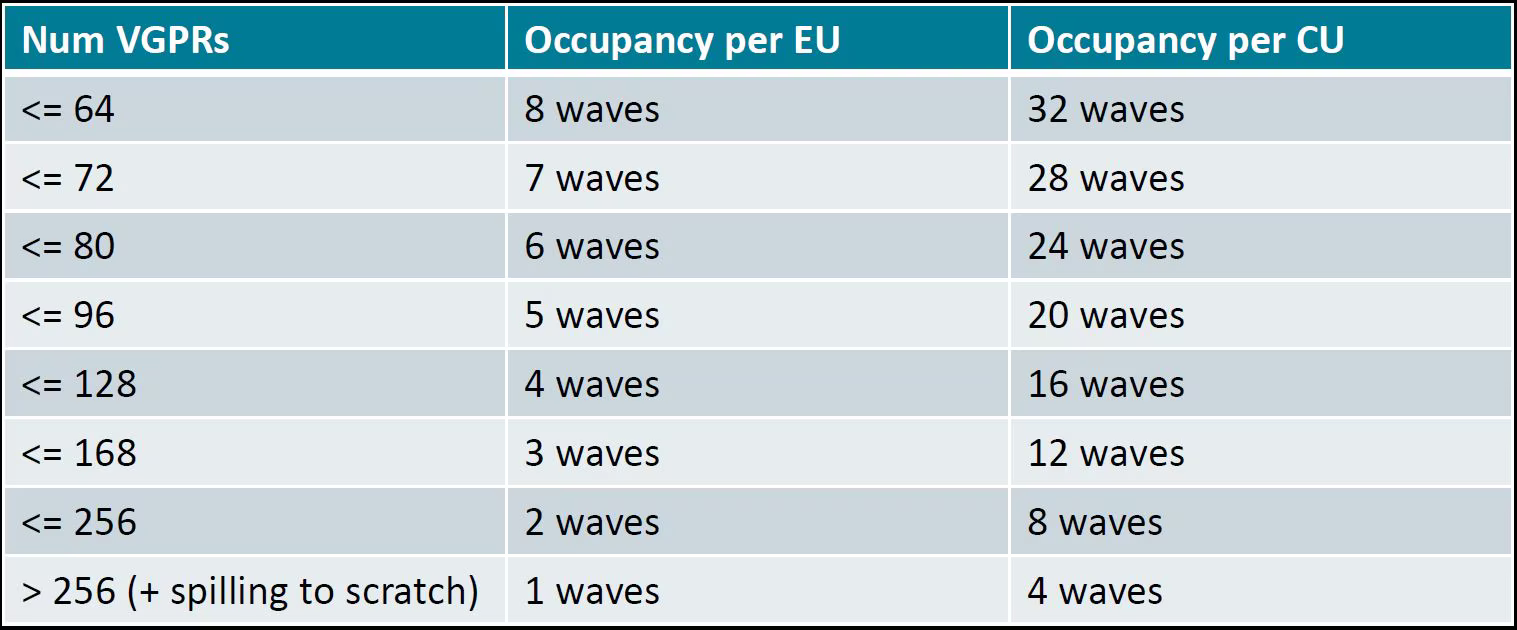
Occupancy related to VGPRs usage on an Instinct MI300X GPU#
For example, according to the table, each Execution Unit (EU) has 512 available
VGPRs, which are allocated in blocks of 16. If the current VGPR usage is 170,
it will be rounded up to 176 due to the allocation granularity. In this case,
the occupancy is limited to 2 waves per EU because \(176 \times 3 > 512\).
So, if you set waves_per_eu to 3, the LLVM backend will attempt to reduce
VGPR usage so that it might fit 3 waves per EU.
BLOCK_M,BLOCK_N,BLOCK_KTile sizes to be tuned to balance the memory-to-computation ratio. The goal is to minimize the memory transfer from global to shared and reuse memory across different threads. This needs to be tuned. The tile sizes should be large enough to maximize the efficiency of the memory-to-computation ratio but small enough to parallelize the greatest number of workgroups at the grid level.
matrix_instr_nonkdimExperimental feature for Flash Attention-like kernels that determines the size of the Matrix Fused Multiply-Add (MFMA) instruction used.
matrix_instr_nonkdim = 16:mfma_16x16is used.matrix_instr_nonkdim = 32:mfma_32x32is used.
For GEMM kernels on an MI300X GPU,
mfma_16x16typically outperformsmfma_32x32, even for large tile/GEMM sizes.
Overall GPU resource utilization#
As depicted in the following figure, each XCD in MI300X contains 40 compute units (CUs), with 38 active. Each MI300X contains eight vertical XCDs, and a total of 304 active compute units capable of parallel computation. The first consideration is the number of CUs a kernel can distribute its task across.
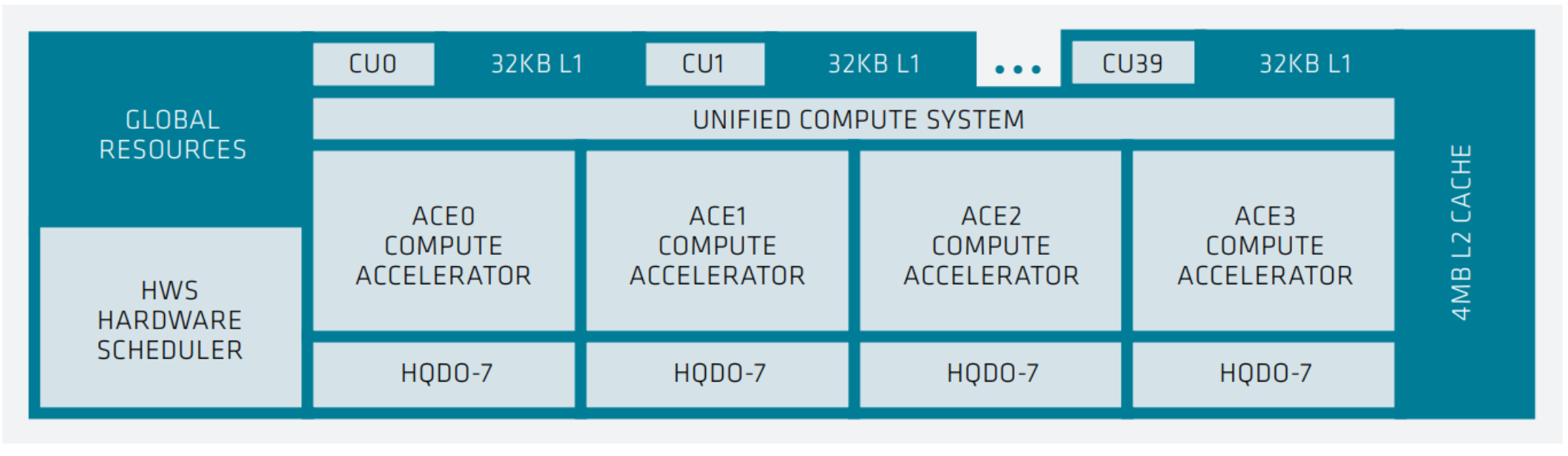
XCD-level system architecture showing 40 compute units, each with 32 KB L1 cache, a unified compute system with 4 ACE compute GPUs, shared 4MB of L2 cache, and a hardware scheduler (HWS).#
You can query hardware resources with the command rocminfo in the
/opt/rocm/bin directory. For instance, query the number of CUs, number of
SIMD, and wavefront size using the following commands.
rocminfo | grep "Compute Unit"
rocminfo | grep "SIMD"
rocminfo | grep "Wavefront Size"
For the MI300X, the goal is to have a minimum of 1024 thread blocks or workgroups in the grid (kernel), with a preference for more.
Identifying additional parallelism within the algorithm is necessary to enhance GPU utilization. For more information and examples, see Accelerating A Triton Fused Kernel For W4a16 Quantized Inference With SplitK Work Decomposition.
MLIR analysis#
Triton includes the following layouts: blocked, shared, sliced, and MFMA.
Use the Triton GPU Intermediate Representation (IR) to identify the memory in which each computation takes place.
Use the environment variable MLIR_ENABLE_DUMP to dump MLIR:
export MLIR_ENABLE_DUMP=1
The following is a snippet of IR from the Flash Attention decode int4 KV program. It is to
de-quantize the int4 key-value from the int4 data type to fp16.
%190 = tt.load %189 {cache = 1 : i32, evict = 1 : i32, isVolatile =
false} : tensor<1x64xi32, #blocked6> loc(#loc159)
%266 = arith.andi %190, %cst_28 : tensor<1x64xi32, #blocked6>
loc(#loc250)
%267 = arith.trunci %266 : tensor<1x64xi32, #blocked6> to
tensor<1x64xi16, #blocked6> loc(#loc251)
%268 = tt.bitcast %267 : tensor<1x64xi16, #blocked6> -> tensor<1x64xf16,
#blocked6> loc(#loc252)
%269 = triton_gpu.convert_layout %268 : (tensor<1x64xf16, #blocked6>) ->
tensor<1x64xf16, #shared1> loc(#loc252)
%270 = tt.trans %269 : (tensor<1x64xf16, #shared1>) -> tensor<64x1xf16,
#shared2> loc(#loc194)
%276 = triton_gpu.convert_layout %270 : (tensor<64x1xf16, #shared2>) ->
tensor<64x1xf16, #blocked5> loc(#loc254)
%293 = arith.mulf %276, %cst_30 : tensor<64x1xf16, #blocked5>
loc(#loc254)
%295 = arith.mulf %292, %294 : tensor<64x32xf16, #blocked5> loc(#loc264)
%297 = arith.addf %295, %296 : tensor<64x32xf16, #blocked5> loc(#loc255)
%298 = triton_gpu.convert_layout %297 : (tensor<64x32xf16, #blocked5>)
-> tensor<64x32xf16, #shared1> loc(#loc255)
%299 = tt.trans %298 : (tensor<64x32xf16, #shared1>) ->
tensor<32x64xf16, #shared2> loc(#loc196)
%300 = triton_gpu.convert_layout %299 : (tensor<32x64xf16, #shared2>) ->
tensor<32x64xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mfma, kWidth
= 4}>> loc(#loc197)
From the IR snippet, you can see i32 data is loaded from global memory to
registers (%190). With a few element-wise operations in registers, it is
stored in shared memory (%269) for the transpose operation (%270), which
needs data movement across different threads. With the transpose done, it is
loaded from LDS to register again (%276), and with a few more
element-wise operations, it is stored to LDS again (%298). The last step
loads from LDS to registers and converts to the dot-operand layout
(%300).
The IR snippet uses the LDS twice. The first is for the transpose, and the second is to convert a blocked layout to a dot operand layout. There’s an opportunity to optimize performance by using LDS once.
ISA assembly analysis#
To generate ISA, export AMDGCN_ENABLE_DUMP=1 when running the Triton
program. The generated ISA will be printed as standard output. You can
dump it to a file for analysis.
Ensure
global_load_dwordx4is used in the ISA, especially when the global memory load happens in the loop.In most cases, the LDS load and store should use
_b128to minimize the number of LDS access instructions.The AMD ISA has
s_waitcntinstruction to synchronize the dependency of memory access and computations. Thes_waitcntinstructions can typically have two signals in the Triton context:lgkmcnt(n):lgkmstands for LDS, GDS (Global Data Share), Constant, and Message. It is often related to LDS access. Thenindicates the number of data accesses can still be ongoing before moving on to the next step. For example, ifnis0, wait for alllgkmaccess to finish before continuing. Ifnis1, move on even if1lgkmaccess is still running asynchronously.vmcnt(n):vmrepresents vector memory. This happens when vector memory is accessed, for example, when global load moves from global memory to vector memory. The variablenis the same as the previous setting.
Generally recommended guidelines are as follows.
Vectorize memory access as much as possible.
Ensure synchronization is done efficiently.
Overlap of instructions to hide latency, but it requires thoughtful analysis of the algorithms.
If you find inefficiencies, you can trace it back to LLVM IR, TTGIR and even TTIR to see where the problem comes from. If you find it during compiler optimization, activate the MLIR dump (
export MLIR_ENABLE_DUMP=1) and check which optimization pass caused the problem.
HIP performance optimization#
This section summarizes the best practices described in the Performance guidelines section of the HIP documentation.
Optimization areas of concern include:
Parallel execution
Memory usage optimization
Optimization for maximum throughput
Minimizing memory thrashing
Parallel execution and GPU hardware utilization#
The application should reveal and efficiently imply as much parallelism as possible for optimal use to keep all system components active.
Memory usage optimization#
To optimize memory throughput, minimize low-bandwidth data transfers, particularly between the host and device. Maximize on-chip memory, including shared memory and caches, to reduce data transfers between global memory and the device.
In a GPU, global memory has high latency but a large size, while local data share (LDS) has lower latency but a smaller size, and registers have the fastest but smallest access. Aim to limit load/store operations in global memory. If multiple threads in a block need the same data, transfer it from global memory to LDS for efficient access.
See HIP’s performance guidelines for greater detail.
Diagnostic and performance analysis#
Debug memory access faults#
Identifying a faulting kernel is often enough to triage a memory access fault. The ROCr Debug Agent can trap a memory access fault and provide a dump of all active wavefronts that caused the error, as well as the name of the kernel. For more information, see ROCr Debug Agent documentation.
To summarize, the key points include:
Compiling with
-ggdb -O0is recommended but not required.HSA_TOOLS_LIB=/opt/rocm/lib/librocm-debug-agent.so.2 HSA_ENABLE_DEBUG=1 ./my_program
When the debug agent traps the fault, it produces verbose output of all wavefront registers and memory content. Importantly, it also prints something similar to the following:
Disassembly for function vector_add_assert_trap(int*, int*, int*):
code object:
file:////rocm-debug-agent/build/test/rocm-debug-agent-test#offset=14309&size=31336
loaded at: [0x7fd4f100c000-0x7fd4f100e070]
The kernel name and the code object file should be listed. In the example above, the kernel name is vector_add_assert_trap, but this might also look like:
Disassembly for function memory:///path/to/codeobject#offset=1234&size=567:
In this case, it’s an in-memory kernel that was generated at runtime.
Using the environment variable ROCM_DEBUG_AGENT_OPTIONS="--all --save-code-objects"
will have the debug agent save all code objects to the current directory. Use
--save-code-objects=[DIR] to save them in another location.
The code objects will be renamed from the URI format with special
characters replaced by ‘_’. Use llvm-objdump to disassemble the
indicated in-memory code object that has been saved to disk. The name of
the kernel is often found in the disassembled code object.
llvm-objdump --disassemble-all path/to/code-object.co
Disabling memory caching strategies within the ROCm stack and PyTorch is recommended, where possible. This gives the debug agent the best chance of finding the memory fault where it originates. Otherwise, it could be masked by writing past the end of a cached block within a larger allocation.
PYTORCH_NO_HIP_MEMORY_CACHING=1
HSA_DISABLE_FRAGMENT_ALLOCATOR=1
Compute the occupancy of a kernel#
Get the VGPR count, search for
.vgpr_countin the ISA (for example,N).Get the allocated LDS following the steps (for example, L for the kernel).
export MLIR_ENABLE_DUMP=1rm -rf ~/.triton/cachepython kernel.py | | grep "triton_gpu.shared = " | tail -n 1You should see something like
triton_gpu.shared = 65536, indicating 65536 bytes of LDS are allocated for the kernel.
Get number of waves per workgroup using the following steps (for example,
nW).export MLIR_ENABLE_DUMP=1rm -rf ~/.triton/cachepython kernel.py | | grep "triton_gpu.num-warps " | tail -n 1You should see something like
“triton_gpu.num-warps" = 8, indicating 8 waves per workgroup.
Compute occupancy limited by VGPR based on N according to the preceding table. For example, waves per EU as
occ_vgpr.Compute occupancy limited by LDS based on L by:
occ_lds = floor(65536 / L).Then the occupancy is
occ = min(floor(occ_vgpr * 4 / nW), occ_lds) * nW / 4occ_vgpr \* 4gives the total number of waves on all 4 execution units (SIMDs) per CU.floor(occ_vgpr * 4 / nW)gives the occupancy of workgroups per CU regrading VGPR usage.The true
occis the minimum of the two.
Find the full occ.sh at
ROCm/triton.
Special considerations#
Multi-GPU communications#
Because of the characteristics of MI300X inter-GPU communication and limitation of bandwidth between and among 2 GPUs and 4 GPUs, avoid running workloads that use 2 or 4 GPU collectives. It’s optimal to either use a single GPU (where no collective is required) or employ 8 GPU collectives.
Multi-node FSDP and RCCL settings#
When using PyTorch’s FSDP (Full Sharded Data Parallel) feature, the HIP streams used by RCCL and HIP streams used for compute kernels do not always overlap well. As a workaround, it’s recommended to use high-priority HIP streams with RCCL.
To configure high-priority streams:
Set environment variable
TORCH_NCCL_HIGH_PRIORITY=1to force all RCCL streams to be high-priority.Set environment variable
GPU_MAX_HW_QUEUES=2via the HIP runtime library.
Hardware efficiency is maximized with 4 or fewer HIP streams. These environment variables limit the configuration to two compute streams and two RCCL streams, aligning with this best practice. Additionally, RCCL is often pre-optimized for MI300 systems in production by querying the node topology during startup, reducing the need for extensive manual tuning.