AMD Instinct™ MI300 Series microarchitecture#
2026-03-29
5 min read time
The AMD Instinct MI300 Series GPUs are based on the AMD CDNA 3 architecture which was designed to deliver leadership performance for HPC, artificial intelligence (AI), and machine learning (ML) workloads. The AMD Instinct MI300 Series GPUs are well-suited for extreme scalability and compute performance, running on everything from individual servers to the world’s largest exascale supercomputers.
With the MI300 Series, AMD is introducing the Accelerator Complex Die (XCD), which contains the GPU computational elements of the processor along with the lower levels of the cache hierarchy.
The following image depicts the structure of a single XCD in the AMD Instinct MI300 GPU Series.
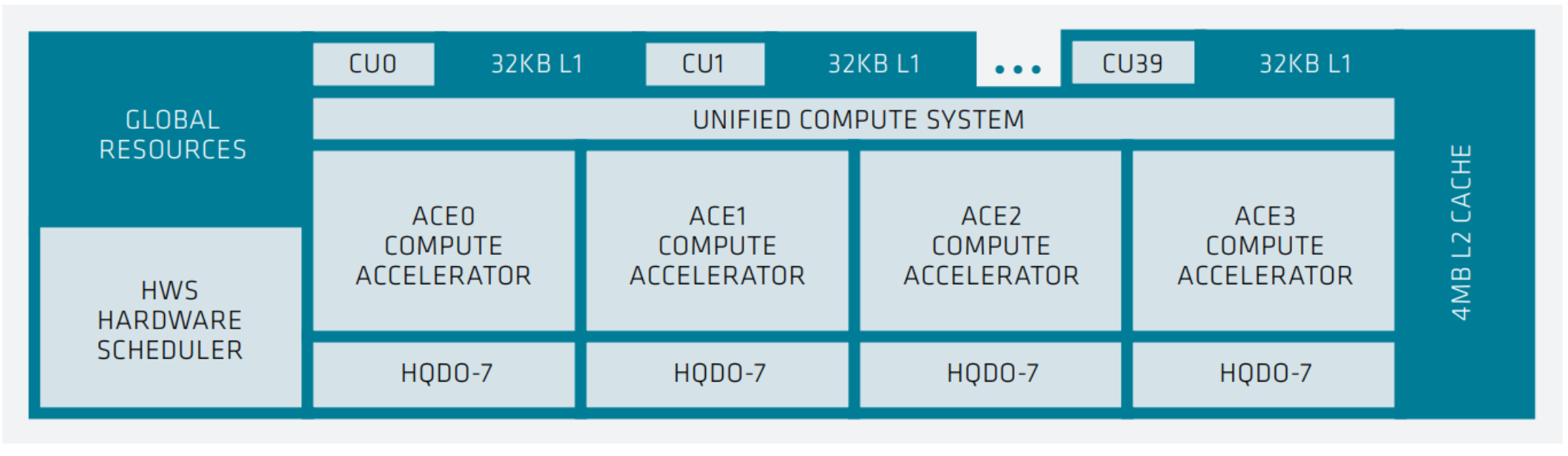
XCD-level system architecture showing 40 Compute Units, each with 32 KB L1 cache, a Unified Compute System with 4 ACE Compute Accelerators, shared 4MB of L2 cache and an HWS Hardware Scheduler.#
On the XCD, four Asynchronous Compute Engines (ACEs) send compute shader workgroups to the Compute Units (CUs). The XCD has 40 CUs: 38 active CUs at the aggregate level and 2 disabled CUs for yield management. The CUs all share a 4 MB L2 cache that serves to coalesce all memory traffic for the die. With less than half of the CUs of the AMD Instinct MI200 Series compute die, the AMD CDNA™ 3 XCD die is a smaller building block. However, it uses more advanced packaging and the processor can include 6 or 8 XCDs for up to 304 CUs, roughly 40% more than MI250X.
The MI300 Series integrate up to 8 vertically stacked XCDs, 8 stacks of High-Bandwidth Memory 3 (HBM3) and 4 I/O dies (containing system infrastructure) using the AMD Infinity Fabric™ technology as interconnect.
The Matrix Cores inside the CDNA 3 CUs have significant improvements, emphasizing AI and machine learning, enhancing throughput of existing data types while adding support for new data types. CDNA 2 Matrix Cores support FP16 and BF16, while offering INT8 for inference. Compared to MI250X GPUs, CDNA 3 Matrix Cores triple the performance for FP16 and BF16, while providing a performance gain of 6.8 times for INT8. FP8 has a performance gain of 16 times compared to FP32, while TF32 has a gain of 4 times compared to FP32.
Computation and Data Type |
FLOPS/CLOCK/CU |
Peak TFLOPS |
|---|---|---|
Matrix FP64 |
256 |
163.4 |
Vector FP64 |
128 |
81.7 |
Matrix FP32 |
256 |
163.4 |
Vector FP32 |
256 |
163.4 |
Vector TF32 |
1024 |
653.7 |
Matrix FP16 |
2048 |
1307.4 |
Matrix BF16 |
2048 |
1307.4 |
Matrix FP8 |
4096 |
2614.9 |
Matrix INT8 |
4096 |
2614.9 |
The above table summarizes the aggregated peak performance of the AMD Instinct MI300X Open Compute Platform (OCP) Open Accelerator Modules (OAMs) for different data types and command processors. The middle column lists the peak performance (number of data elements processed in a single instruction) of a single compute unit if a SIMD (or matrix) instruction is submitted in each clock cycle. The third column lists the theoretical peak performance of the OAM. The theoretical aggregated peak memory bandwidth of the GPU is 5.3 TB per second.
The following image shows the block diagram of the APU (left) and the OAM package (right) both connected via AMD Infinity Fabric™ network on-chip.
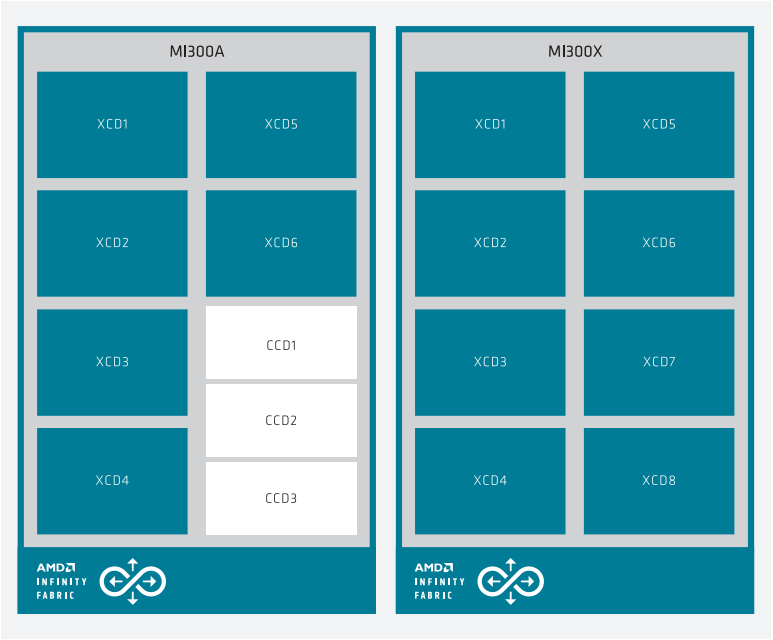
MI300 Series system architecture showing MI300A (left) with 6 XCDs and 3 CCDs, while the MI300X (right) has 8 XCDs.#
Node-level architecture#
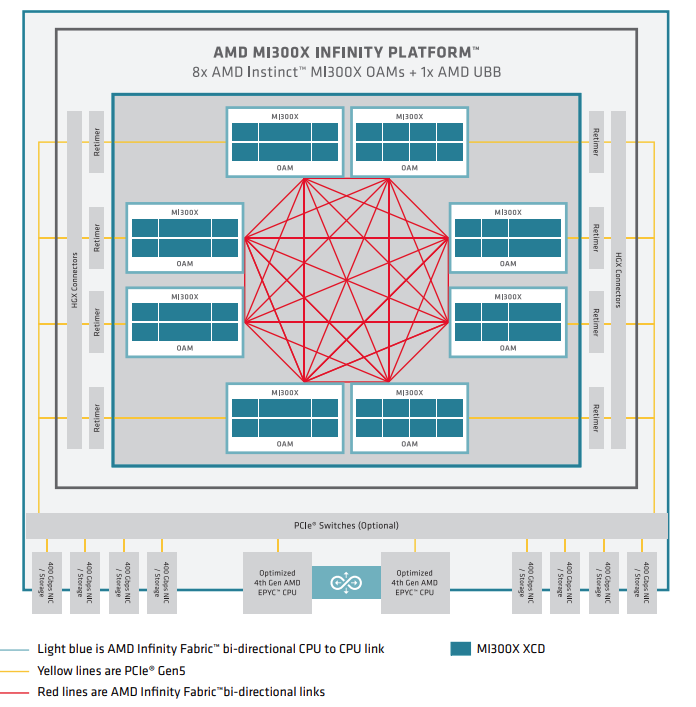
MI300 Series node-level architecture showing 8 fully interconnected MI300X OAM modules connected to (optional) PCIEe switches via retimers and HGX connectors.#
The image above shows the node-level architecture of a system with AMD EPYC processors in a dual-socket configuration and eight AMD Instinct MI300X GPUs. The MI300X OAMs attach to the host system via PCIe Gen 5 x16 links (yellow lines). The GPUs are using seven high-bandwidth, low-latency AMD Infinity Fabric™ links (red lines) to form a fully connected 8-GPU system.