Training a model with ROCm Megatron-LM#
2024-12-16
16 min read time
The ROCm Megatron-LM framework is a specialized fork of the robust Megatron-LM, designed to enable efficient training of large-scale language models on AMD GPUs. By leveraging AMD Instinct™ MI300X accelerators, AMD Megatron-LM delivers enhanced scalability, performance, and resource utilization for AI workloads. It is purpose-built to support models like Meta’s Llama 2, Llama 3, and Llama 3.1, enabling developers to train next-generation AI models with greater efficiency. See the GitHub repository at ROCm/Megatron-LM.
For ease of use, AMD provides a ready-to-use Docker image for MI300X accelerators containing essential components, including PyTorch, PyTorch Lightning, ROCm libraries, and Megatron-LM utilities. It contains the following software to accelerate training workloads:
Software component |
Version |
|---|---|
ROCm |
6.1 |
PyTorch |
2.4.0 |
PyTorch Lightning |
2.4.0 |
Megatron Core |
0.9.0 |
Transformer Engine |
1.5.0 |
Flash Attention |
v2.6 |
Transformers |
4.44.0 |
Supported features and models#
Megatron-LM provides the following key features to train large language models efficiently:
Transformer Engine (TE)
APEX
GEMM tuning
Torch.compile
3D parallelism: TP + SP + CP
Distributed optimizer
Flash Attention (FA) 2
Fused kernels
Pre-training
The following models are pre-optimized for performance on the AMD Instinct MI300X accelerator.
Llama 2 7B
Llama 2 70B
Llama 3 8B
Llama 3 70B
Llama 3.1 8B
Llama 3.1 70B
Prerequisite system validation steps#
Complete the following system validation and optimization steps to set up your system before starting training.
Disable NUMA auto-balancing#
Generally, application performance can benefit from disabling NUMA auto-balancing. However, it might be detrimental to performance with certain types of workloads.
Run the command cat /proc/sys/kernel/numa_balancing to check your current NUMA (Non-Uniform
Memory Access) settings. Output 0 indicates this setting is disabled. If there is no output or
the output is 1, run the following command to disable NUMA auto-balancing.
sudo sh -c 'echo 0 > /proc/sys/kernel/numa_balancing'
See Disable NUMA auto-balancing for more information.
Hardware verification with ROCm#
Use the command rocm-smi --setperfdeterminism 1900 to set the max clock speed up to 1900 MHz
instead of the default 2100 MHz. This can reduce the chance of a PCC event lowering the attainable
GPU clocks. This setting will not be required for new IFWI releases with the production PRC feature.
You can restore this setting to its default value with the rocm-smi -r command.
Run the command:
rocm-smi --setperfdeterminism 1900
See Hardware verification with ROCm for more information.
RCCL Bandwidth Test#
ROCm Collective Communications Library (RCCL) is a standalone library of standard collective communication routines for GPUs. See the RCCL documentation for more information. Before starting pre-training, running a RCCL bandwidth test helps ensure that the multi-GPU or multi-node setup is optimized for efficient distributed training.
Running the RCCL bandwidth test helps verify that:
The GPUs can communicate across nodes or within a single node.
The interconnect (such as InfiniBand, Ethernet, or Infinite fabric) is functioning as expected and provides adequate bandwidth for communication.
No hardware setup or cabling issues could affect the communication between GPUs
Tuning and optimizing hyperparameters#
In distributed training, specific hyperparameters related to distributed communication can be tuned based on the results of the RCCL bandwidth test. These variables are already set in the Docker image:
# force all RCCL streams to be high priority
export TORCH_NCCL_HIGH_PRIORITY=1
# specify which RDMA interfaces to use for communication
export NCCL_IB_HCA=rdma0,rdma1,rdma2,rdma3,rdma4,rdma5,rdma6,rdma7
# define the Global ID index used in RoCE mode
export NCCL_IB_GID_INDEX=3
# avoid data corruption/mismatch issue that existed in past releases
export RCCL_MSCCL_ENABLE=0
Running the RCCL Bandwidth Test#
It’s recommended you run the RCCL bandwidth test before launching training. It ensures system performance is sufficient to launch training. RCCL is not included in the AMD Megatron-LM Docker image; follow the instructions in ROCm/rccl-tests to get started. See RCCL for more information.
Run on 8 GPUs (-g 8), scanning from 8 bytes to 10 GB:
./build/all_reduce_perf -b 8 -e 10G -f 2 -g 8
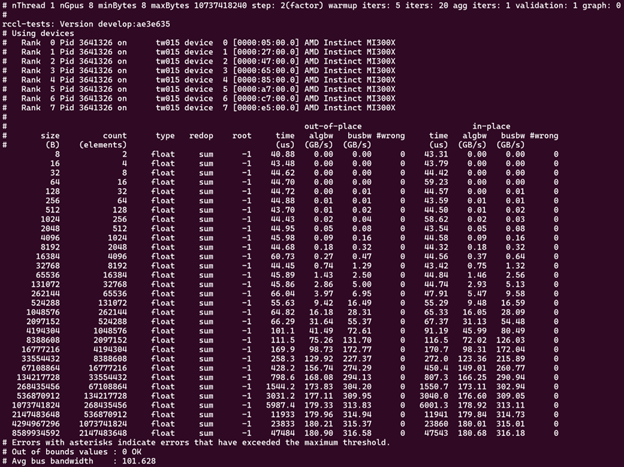
Using one MPI process per GPU and -g 1 for performance-oriented runs on both single-node and multi-node is
recommended. So, a run on 8 GPUs looks something like:
mpirun -np 8 --bind-to numa ./build/all_reduce_perf -b 8 -e 10G -f 2 -g 1
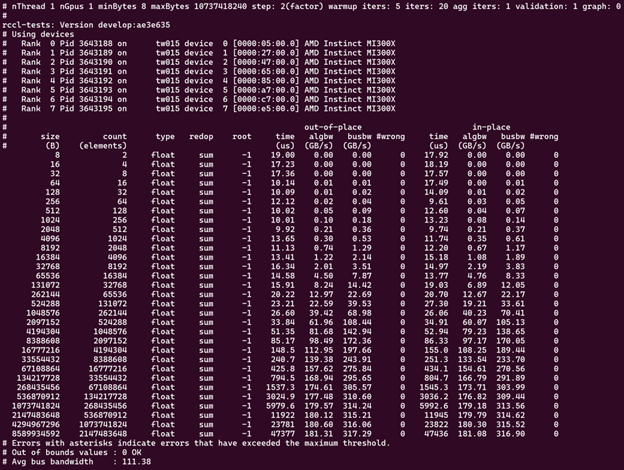
Running with one MPI process per GPU ensures a one-to-one mapping for CPUs and GPUs, which can be beneficial for smaller message sizes. This better represents the real-world use of RCCL in deep learning frameworks like PyTorch and TensorFlow.
Use the following script to run the RCCL test for four MI300X GPU nodes. Modify paths and node addresses as needed.
/home/$USER/ompi_for_gpu/ompi/bin/mpirun -np 32 -H tw022:8,tw024:8,tw010:8, tw015:8 \
--mca pml ucx \
--mca btl ^openib \
-x NCCL_SOCKET_IFNAME=ens50f0np0 \
-x NCCL_IB_HCA=rdma0:1,rdma1:1,rdma2:1,rdma3:1,rdma4:1,rdma5:1,rdma6:1,rdma7:1 \
-x NCCL_IB_GID_INDEX=3 \
-x NCCL_MIN_NCHANNELS=40 \
-x NCCL_DEBUG=version \
$HOME/rccl-tests/build/all_reduce_perf -b 8 -e 8g -f 2 -g 1
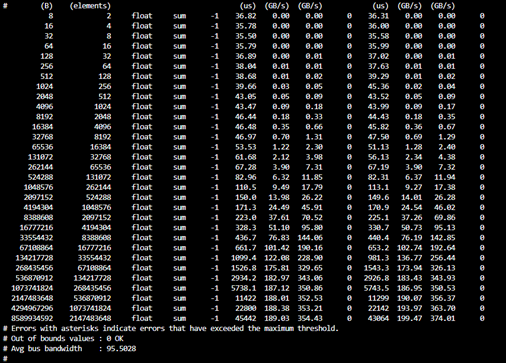
Start training on MI300X accelerators#
The pre-built ROCm Megatron-LM environment allows users to quickly validate system performance, conduct training benchmarks, and achieve superior performance for models like Llama 2 and Llama 3.1.
Use the following instructions to set up the environment, configure the script to train models, and reproduce the benchmark results on the MI300X accelerators with the AMD Megatron-LM Docker image.
Download the Docker image and required packages#
Use the following command to pull the Docker image from Docker Hub.
docker pull rocm/megatron-lm:24.12-dev
Launch the Docker container.
docker run -it --device /dev/dri --device /dev/kfd --network host --ipc host --group-add video --cap-add SYS_PTRACE --security-opt seccomp=unconfined --privileged -v $CACHE_DIR:/root/.cache --name megatron-dev-env rocm/megatron-lm:24.12-dev /bin/bash
Clone the ROCm Megatron-LM repository to a local directory and install the required packages on the host machine.
git clone https://github.com/ROCm/Megatron-LM cd Megatron-LM
Note
This release is validated with
ROCm/Megatron-LMcommit bb93ccb. Checking out this specific commit is recommended for a stable and reproducible environment.git checkout bb93ccbfeae6363c67b361a97a27c74ab86e7e92
Prepare training datasets#
If you already have the preprocessed data, you can skip this section.
Use the following command to process datasets. We use GPT data as an example. You may change the merge table, use an end-of-document token, remove sentence splitting, and use the tokenizer type.
python tools/preprocess_data.py \
--input my-corpus.json \
--output-prefix my-gpt2 \
--vocab-file gpt2-vocab.json \
--tokenizer-type GPT2BPETokenizer \
--merge-file gpt2-merges.txt \
--append-eod
In this case, the automatically generated output files are named my-gpt2_text_document.bin and
my-gpt2_text_document.idx.

Environment setup#
In the examples/llama directory of Megatron-LM, if you’re working with Llama 2 7B or Llama 2 70 B, use the
train_llama2.sh configuration script. Likewise, if you’re working with Llama 3 or Llama 3.1, then use
train_llama3.sh and update the configuration script accordingly.
Network interface#
To avoid connectivity issues, ensure the correct network interface is set in your training scripts.
Run the following command to find the active network interface on your system.
ip aUpdate the
NCCL_SOCKET_IFNAMEandGLOO_SOCKET_IFNAMEvariables with your system’s network interface. For example:export NCCL_SOCKET_IFNAME=ens50f0np0 export GLOO_SOCKET_IFNAME=ens50f0np0
Dataset options#
You can use either mock data or real data for training.
If you’re using a real dataset, update the
DATA_PATHvariable to point to the location of your dataset.DATA_DIR="/root/.cache/data" # Change to where your dataset is stored DATA_PATH=${DATA_DIR}/bookcorpus_text_sentence
--data-path $DATA_PATH
Ensure that the files are accessible inside the Docker container.
Mock data can be useful for testing and validation. If you’re using mock data, replace
--data-path $DATA_PATHwith the--mock-dataoption.--mock-data
Tokenizer#
Tokenization is the process of converting raw text into tokens that can be processed by the model. For Llama models, this typically involves sub-word tokenization, where words are broken down into smaller units based on a fixed vocabulary. The tokenizer is trained along with the model on a large corpus of text, and it learns a fixed vocabulary that can represent a wide range of text from different domains. This allows Llama models to handle a variety of input sequences, including unseen words or domain-specific terms.
To train any of the Llama 2 models that this Docker image supports, use the Llama2Tokenizer.
To train any of Llama 3 and Llama 3.1 models that this Docker image supports, use the HuggingFaceTokenizer.
Set the Hugging Face model link in the TOKENIZER_MODEL variable.
For example, if you’re using the Llama 3.1 8B model:
TOKENIZER_MODEL=meta-llama/Llama-3.1-8B
Run benchmark tests#
Note
If you’re running multi node training, update the following environment variables. They can also be passed as command line arguments.
Change
localhostto the master node’s hostname:MASTER_ADDR="${MASTER_ADDR:-localhost}"
Set the number of nodes you want to train on (for instance,
2,4,8):NNODES="${NNODES:-1}"
Set the rank of each node (0 for master, 1 for the first worker node, and so on):
NODE_RANK="${NODE_RANK:-0}"
Use this command to run a performance benchmark test of any of the Llama 2 models that this Docker image supports (see variables).
{variables} bash examples/llama/train_llama2.sh
Use this command to run a performance benchmark test of any of the Llama 3 and Llama 3.1 models that this Docker image supports (see variables).
{variables} bash examples/llama/train_llama3.sh
The benchmark tests support the same set of variables:
Name |
Options |
Description |
|---|---|---|
|
0 or 1 |
0: disable training log 1: enable training log |
|
Micro batch size |
|
|
Batch size |
|
|
1, 2, 4, 8 |
Tensor parallel |
|
0 or 1 |
Datatype. If it is set to 1, FP8. If it is set to 0. BP16 |
|
0 or 1 |
If it is set to 1, enable torch.compile. If it is set to 0. Disable torch.compile (default) |
|
Input sequence length |
|
|
0 or 1 |
If it is set to 1, enable gemm tuning. If it is set to 0, disable gemm tuning |
|
0 or 1 |
0: disable flash attention 1: enable flash attention |
|
0 or 1 |
0: disable torch profiling 1: enable torch profiling |
|
The size of the mode: 7B/70B, etc. |
|
|
Total number of iterations |
|
|
transformer_engine or local |
Enable transformer engine by default |
Benchmarking examples#
Use this command to run training with Llama 2 7B model on a single node. You can specify MBS, BS, FP, datatype, and so on.
TEE_OUTPUT=1 MBS=5 BS=120 TP=8 TE_FP8=0 NO_TORCH_COMPILE=1
SEQ_LENGTH=4096 bash examples/llama/train_llama2.sh
You can find the training logs at the location defined in $TRAIN_LOG in the configuration script.
See the sample output:

Launch the Docker container on each node.
In this example, run training with Llama 2 7B model on 2 nodes with specific MBS, BS, FP, datatype, and so on.
On the master node:
TEE_OUTPUT=1 MBS=4 BS=64 TP=8 TE_FP8=0 NO_TORCH_COMPILE=1
SEQ_LENGTH=4096 bash examples/llama/train_llama2.sh
On the worker node:
TEE_OUTPUT=1 MBS=4 BS=64 TP=8 TE_FP8=0 NO_TORCH_COMPILE=1
SEQ_LENGTH=4096 bash examples/llama/train_llama2.sh
You can find the training logs at the location defined in $TRAIN_LOG in the configuration script.
Sample output for 2-node training:
Master node:

Worker node:
