GPU-Enabled MPI#
2023-08-08
9 min read time
The Message Passing Interface (MPI) is a standard API for distributed and parallel application development that can scale to multi-node clusters. To facilitate the porting of applications to clusters with GPUs, ROCm enables various technologies. These technologies allow users to directly use GPU pointers in MPI calls and enable ROCm-aware MPI libraries to deliver optimal performance for both intra-node and inter-node GPU-to-GPU communication.
The AMD kernel driver exposes Remote Direct Memory Access (RDMA) through the
PeerDirect interfaces to allow Host Channel Adapters (HCA, a type of
Network Interface Card or NIC) to directly read and write to the GPU device
memory with RDMA capabilities. These interfaces are currently registered as a
peer_memory_client with Mellanox’s OpenFabrics Enterprise Distribution (OFED)
ib_core kernel module to allow high-speed DMA transfers between GPU and HCA.
These interfaces are used to optimize inter-node MPI message communication.
This chapter exemplifies how to set up Open MPI with the ROCm platform. The Open MPI project is an open source implementation of the Message Passing Interface (MPI) that is developed and maintained by a consortium of academic, research, and industry partners.
Several MPI implementations can be made ROCm-aware by compiling them with Unified Communication Framework (UCX) support. One notable exception is MVAPICH2: It directly supports AMD GPUs without using UCX, and you can download it here. Use the latest version of the MVAPICH2-GDR package.
The Unified Communication Framework, is an open source cross-platform framework whose goal is to provide a common set of communication interfaces that targets a broad set of network programming models and interfaces. UCX is ROCm-aware, and ROCm technologies are used directly to implement various network operation primitives. For more details on the UCX design, refer to it’s documentation.
Building UCX#
The following section describes how to set up UCX so it can be used to compile Open MPI. The following environment variables are set, such that all software components will be installed in the same base directory (we assume to install them in your home directory; for other locations adjust the below environment variables accordingly, and make sure you have write permission for that location):
export INSTALL_DIR=$HOME/ompi_for_gpu
export BUILD_DIR=/tmp/ompi_for_gpu_build
mkdir -p $BUILD_DIR
The following sequences of build commands assume either the ROCmCC or the AOMP
compiler is active in the environment, which will execute the commands.
Install UCX#
The next step is to set up UCX by compiling its source code and install it:
export UCX_DIR=$INSTALL_DIR/ucx
cd $BUILD_DIR
git clone https://github.com/openucx/ucx.git -b v1.14.1
cd ucx
./autogen.sh
mkdir build
cd build
../configure -prefix=$UCX_DIR \
--with-rocm=/opt/rocm
make -j $(nproc)
make -j $(nproc) install
The following table documents the compatibility of UCX versions with ROCm versions.
Install Open MPI#
These are the steps to build Open MPI:
export OMPI_DIR=$INSTALL_DIR/ompi
cd $BUILD_DIR
git clone --recursive https://github.com/open-mpi/ompi.git \
-b v5.0.x
cd ompi
./autogen.pl
mkdir build
cd build
../configure --prefix=$OMPI_DIR --with-ucx=$UCX_DIR \
--with-rocm=/opt/rocm
make -j $(nproc)
make -j $(nproc) install
ROCm-enabled OSU#
The OSU Micro Benchmarks v5.9 (OMB) can be used to evaluate the performance of
various primitives with an AMD GPU device and ROCm support. This functionality
is exposed when configured with --enable-rocm option. We can use the following
steps to compile OMB:
export OSU_DIR=$INSTALL_DIR/osu
cd $BUILD_DIR
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.9.tar.gz
tar xfz osu-micro-benchmarks-5.9.tar.gz
cd osu-micro-benchmarks-5.9
./configure --prefix=$INSTALL_DIR/osu --enable-rocm \
--with-rocm=/opt/rocm \
CC=$OMPI_DIR/bin/mpicc CXX=$OMPI_DIR/bin/mpicxx \
LDFLAGS="-L$OMPI_DIR/lib/ -lmpi -L/opt/rocm/lib/ \
$(hipconfig -C) -lamdhip64" CXXFLAGS="-std=c++11"
make -j $(nproc)
Intra-node Run#
Before running an Open MPI job, it is essential to set some environment variables to ensure that the correct version of Open MPI and UCX is being used.
export LD_LIBRARY_PATH=$OMPI_DIR/lib:$UCX_DIR/lib:/opt/rocm/lib
export PATH=$OMPI_DIR/bin:$PATH
The following command runs the OSU bandwidth benchmark between the first two GPU devices (i.e., GPU 0 and GPU 1, same OAM) by default inside the same node. It measures the unidirectional bandwidth from the first device to the other.
$OMPI_DIR/bin/mpirun -np 2 \
-x UCX_TLS=sm,self,rocm \
--mca pml ucx mpi/pt2pt/osu_bw -d rocm D D
To select different devices, for example 2 and 3, use the following command:
export HIP_VISIBLE_DEVICES=2,3
export HSA_ENABLE_SDMA=0
The following output shows the effective transfer bandwidth measured for inter-die data transfer between GPU device 2 and 3 (same OAM). For messages larger than 67MB, an effective utilization of about 150GB/sec is achieved, which corresponds to 75% of the peak transfer bandwidth of 200GB/sec for that connection:
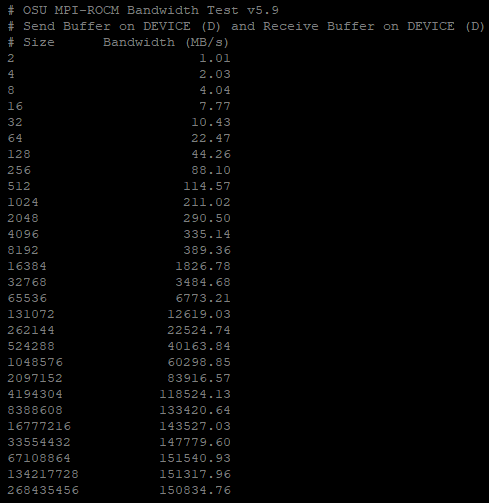
Fig. 53 Inter-GPU bandwidth with various payload sizes.#
Collective Operations#
Collective Operations on GPU buffers are best handled through the Unified Collective Communication Library (UCC) component in Open MPI. For this, the UCC library has to be configured and compiled with ROCm support.
Please note the compatibility table for UCC versions with the various ROCm versions.
An example for configuring UCC and Open MPI with ROCm support is shown below:
export UCC_DIR=$INSTALL_DIR/ucc
git clone https://github.com/openucx/ucc.git
cd ucc
./configure --with-rocm=/opt/rocm \
--with-ucx=$UCX_DIR \
--prefix=$UCC_DIR
make -j && make install
# Configure and compile Open MPI with UCX, UCC, and ROCm support
cd ompi
./configure --with-rocm=/opt/rocm \
--with-ucx=$UCX_DIR \
--with-ucc=$UCC_DIR
--prefix=$OMPI_DIR
To use the UCC component with an MPI application requires setting some additional parameters:
mpirun --mca pml ucx --mca osc ucx \
--mca coll_ucc_enable 1 \
--mca coll_ucc_priority 100 -np 64 ./my_mpi_app