![]()
AMD OpenVX#
The Khronos OpenVX API offers a set of optimized primitives for low-level image processing, computer vision, and neural net operators. The API provides a simple method to write optimized code that is portable across multiple hardware vendors and platforms.
OpenVX allows for resource and execution abstractions, which enable hardware vendors to optimize their implementation for their platform. Performance portability across CPUs, GPUs, and special-function hardware are one of the design goals of the OpenVX specification.
OpenVX is used to build, verify, and coordinate computer vision and neural network graph executions. The graph abstraction enables OpenVX implementation to optimize execution for the underlying hardware. Using optimized OpenVX conformant implementation, software developers can spend more time on algorithmic innovations without worrying about the performance and portability of their applications.
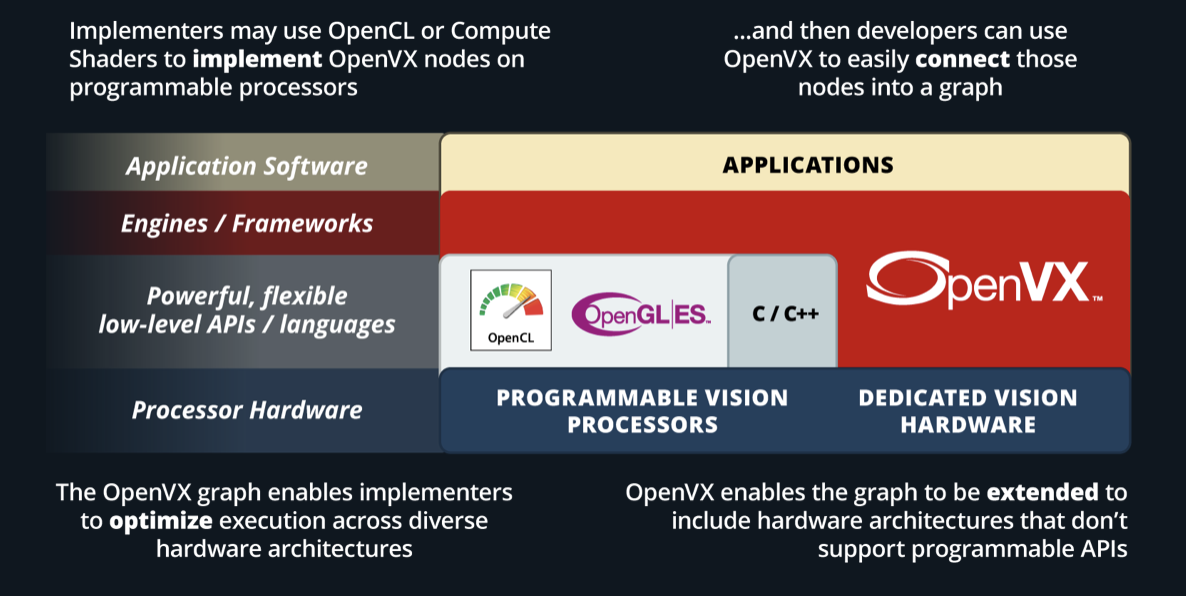
OpenVX specification also defines the VXU or the immediate function library. VXU operators allow developers to use all the OpenVX operators as a directly callable C function without creating a graph first. Applications built using the VXU library do not benefit from the optimizations enabled by graph execution. The VXU library can be the simplest way to use OpenVX and is the first step in porting existing vision applications.
AMD OpenVX is a highly optimized open-source implementation of the Khronos OpenVX 1.3 computer vision specification. It allows for rapid prototyping as well as fast execution on a wide range of computer hardware, including small embedded x86 CPUs and large workstation discrete GPUs.
The amd_openvx project consists of the following components:
OpenVX: AMD OpenVX library
The OpenVX framework provides a mechanism to add new vision functions to OpenVX by 3rd party vendors. Look into amd_openvx_extensions for additional OpenVX modules and utilities.
vx_loomsl: Radeon LOOM stitching library for live 360-degree video applications
vx_nn: OpenVX neural network module that was built on top of MIOpen
vx_opencv: OpenVX module that implemented a mechanism to access OpenCV functionality as OpenVX kernels
vx_rpp: OpenVX extension providing an interface to some of the Radeon Performance Primitives (RPP) functions. This extension is used to enable rocAL to perform image augmentation.
vx_winml: OpenVX module that implemented a mechanism to access Windows Machine Learning(WinML) functionality as OpenVX kernels
Features#
The code is highly optimized for both x86 CPU and OpenCL/HIP for GPU
Supported hardware spans the range from low power embedded APUs, laptops, desktops, and workstation graphics
Supports
Windows,Linux, andmacOSIncludes a “graph optimizer” that looks at the entire processing pipeline and removes/replaces/merges functions to improve performance and minimize bandwidth at runtime
Scripting support with RunVX allows for rapid prototyping, without re-compiling at production performance levels
Pre-requisites#
Build Instructions#
Build this project to generate AMD OpenVX library
Refer to openvx/include/VX for Khronos OpenVX standard header files.
Refer to openvx/include/vx_ext_amd.h for vendor extensions in AMD OpenVX library
Build using Visual Studio#
Install OpenCV with/without contrib download for RunVX tool to support camera capture and image display (optional)
OpenCV_DIR environment variable should point to OpenCV/build folder
Use amd_openvx/amd_openvx.sln to build for x64 platform
If AMD GPU (or OpenCL) is not available, set build flag
ENABLE_OPENCL=0in openvx/openvx.vcxproj and runvx/runvx.vcxproj
Note: AMD GPU HIP backend is not supported on Windows
Build using CMake#
Install CMake 3.0 or later
Use CMake to configure and generate Makefile