Vector L1 cache (vL1D)#
The vector L1 data (vL1D) cache is local to each compute unit on the accelerator, and handles vector memory operations issued by a wavefront. The vL1D cache consists of several components:
An address processing unit, also known as the texture addresser which receives commands (instructions) and write/atomic data from the compute unit, and coalesces them into fewer requests for the cache to process.
An address translation unit, also known as the L1 Unified Translation Cache (UTCL1), that translates requests from virtual to physical addresses for lookup in the cache. The translation unit has an L1 translation lookaside buffer (L1TLB) to reduce the cost of repeated translations.
A Tag RAM that looks up whether a requested cache line is already present in the cache.
The result of the Tag RAM lookup is placed in the L1 cache controller for routing to the correct location; for instance, the L2 Memory Interface for misses or the cache RAM for hits.
The cache RAM, also known as the texture cache (TC), stores requested data for potential reuse. Data returned from the L2 cache is placed into the cache RAM before going down the data-return path.
A backend data processing unit, also known as the texture data (TD) that routes data back to the requesting compute unit.
Together, this complex is known as the vL1D, or Texture Cache per Pipe (TCP). A simplified diagram of the vL1D is presented below:
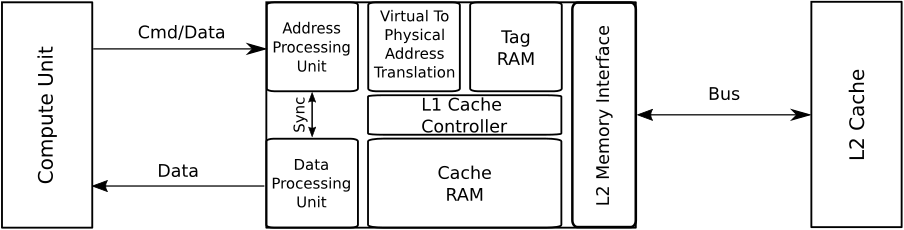
Fig. 46 Performance model of the vL1D Cache on AMD Instinct MI-series accelerators.#
vL1D Speed-of-Light#
Warning
The theoretical maximum throughput for some metrics in this section are
currently computed with the maximum achievable clock frequency, as reported
by rocminfo, for an accelerator. This may not be realistic for all
workloads.
The vL1D’s speed-of-light chart shows several key metrics for the vL1D as a comparison with the peak achievable values of those metrics.
Metric |
Description |
Unit |
|---|---|---|
Hit Rate |
The ratio of the number of vL1D cache line requests that hit [1] in vL1D cache over the total number of cache line requests to the vL1D Cache RAM. |
Percent |
Bandwidth |
The number of bytes looked up in the vL1D cache as a result of VMEM instructions, as a percent of the peak theoretical bandwidth achievable on the specific accelerator. The number of bytes is calculated as the number of cache lines requested multiplied by the cache line size. This value does not consider partial requests, so for instance, if only a single value is requested in a cache line, the data movement will still be counted as a full cache line. |
Percent |
Utilization |
Indicates how busy the vL1D Cache RAM was during the kernel execution. The number of cycles where the vL1D Cache RAM is actively processing any request divided by the number of cycles where the vL1D is active [2]. |
Percent |
Coalescing |
Indicates how well memory instructions were coalesced by the address processing unit, ranging from uncoalesced (25%) to fully coalesced (100%). Calculated as the average number of thread-requests generated per instruction divided by the ideal number of thread-requests per instruction. |
Percent |
Address processing unit or Texture Addresser (TA)#
The vL1D’s address processing unit receives vector memory instructions (commands) along with write/atomic data from a compute unit and is responsible for coalescing these into requests for lookup in the vL1D RAM. The address processor passes information about the commands (coalescing state, destination SIMD, etc.) to the data processing unit for use after the requested data has been retrieved.
Omniperf reports several metrics to indicate performance bottlenecks in the address processing unit, which are broken down into a few categories:
Busy / stall metrics#
When executing vector memory instructions, the compute unit must send an address (and in the case of writes/atomics, data) to the address processing unit. When the front-end cannot accept any more addresses, it must backpressure the wave-issue logic for the VMEM pipe and prevent the issue of further vector memory instructions.
Metric |
Description |
Unit |
|---|---|---|
Busy |
Percent of the total CU cycles the address processor was busy |
Percent |
Address Stall |
Percent of the total CU cycles the address processor was stalled from sending address requests further into the vL1D pipeline |
Percent |
Data Stall |
Percent of the total CU cycles the address processor was stalled from sending write/atomic data further into the vL1D pipeline |
Percent |
Data-Processor → Address Stall |
Percent of total CU cycles the address processor was stalled waiting to send command data to the data processor |
Percent |
Instruction counts#
The address processor also counts instruction types to give the user information on what sorts of memory instructions were executed by the kernel. These are broken down into a few major categories:
Memory type |
Usage |
Description |
|---|---|---|
Global |
Global memory |
Global memory can be seen by all threads from a process. This includes the local accelerator’s DRAM, remote accelerator’s DRAM, and the host’s DRAM. |
Generic |
Dynamic address spaces |
Generic memory, or “flat” memory, is used when the compiler cannot statically prove that a pointer is to memory in one or the other address spaces. The pointer could dynamically point into global, local, constant, or private memory. |
Private Memory |
Register spills / Stack memory |
Private memory, or “scratch” memory, is only visible to a particular work-item in a particular workgroup. On AMD Instinct™ MI-series accelerators, private memory is used to implement both register spills and stack memory accesses. |
The address processor counts these instruction types as follows:
Type |
Description |
Unit |
|---|---|---|
Global/Generic |
The total number of global & generic memory instructions executed on all compute units on the accelerator, per normalization unit. |
Instructions per normalization unit |
Global/Generic Read |
The total number of global & generic memory read instructions executed on all compute units on the accelerator, per normalization unit. |
Instructions per normalization unit |
Global/Generic Write |
The total number of global & generic memory write instructions executed on all compute units on the accelerator, per normalization unit. |
Instructions per normalization unit |
Global/Generic Atomic |
The total number of global & generic memory atomic (with and without return) instructions executed on all compute units on the accelerator, per normalization unit. |
Instructions per normalization unit |
Spill/Stack |
The total number of spill/stack memory instructions executed on all compute units on the accelerator, per normalization unit. |
Instructions per normalization unit |
Spill/Stack Read |
The total number of spill/stack memory read instructions executed on all compute units on the accelerator, per normalization unit. |
Instructions per normalization unit |
Spill/Stack Write |
The total number of spill/stack memory write instructions executed on all compute units on the accelerator, per normalization unit. |
Instruction per normalization unit |
Spill/Stack Atomic |
The total number of spill/stack memory atomic (with and without return) instructions executed on all compute units on the accelerator, per normalization unit. Typically unused as these memory operations are typically used to implement thread-local storage. |
Instructions per normalization unit |
Note
The above is a simplified model specifically for the HIP programming language that does not consider inline assembly usage, constant memory usage or texture memory.
These categories correspond to:
Global/Generic: global and flat memory operations, that are used for global and generic memory access.
Spill/Stack: buffer instructions which are used on the MI50, MI100, and MI2XX accelerators for register spills / stack memory.
These concepts are described in more detail in the Memory spaces, while generic memory access is explored in the generic memory benchmark section.
Spill / stack metrics#
Finally, the address processing unit contains a separate coalescing stage for spill/stack memory, and thus reports:
Metric |
Description |
Unit |
|---|---|---|
Spill/Stack Total Cycles |
The number of cycles the address processing unit spent working on spill/stack instructions, per normalization unit. |
Cycles per normalization unit |
Spill/Stack Coalesced Read Cycles |
The number of cycles the address processing unit spent working on coalesced spill/stack read instructions, per normalization unit. |
Cycles per normalization unit |
Spill/Stack Coalesced Write Cycles |
The number of cycles the address processing unit spent working on coalesced spill/stack write instructions, per normalization unit. |
Cycles per normalization unit |
L1 Unified Translation Cache (UTCL1)#
After a vector memory instruction has been processed/coalesced by the address processing unit of the vL1D, it must be translated from a virtual to physical address. This process is handled by the L1 Unified Translation Cache (UTCL1). This cache contains a L1 Translation Lookaside Buffer (TLB) which stores recently translated addresses to reduce the cost of subsequent re-translations.
Omniperf reports the following L1 TLB metrics:
Metric |
Description |
Unit |
|---|---|---|
Requests |
The number of translation requests made to the UTCL1 per normalization unit. |
Requests per normalization unit |
Hits |
The number of translation requests that hit in the UTCL1, and could be reused, per normalization unit. |
Requests per normalization unit |
Hit Ratio |
The ratio of the number of translation requests that hit in the UTCL1 divided by the total number of translation requests made to the UTCL1. |
Percent |
Translation Misses |
The total number of translation requests that missed in the UTCL1 due to translation not being present in the cache, per normalization unit. |
Requests per normalization unit |
Permission Misses |
The total number of translation requests that missed in the UTCL1 due to a permission error, per normalization unit. This is unused and expected to be zero in most configurations for modern CDNA™ accelerators. |
Requests per normalization unit |
Note
On current CDNA accelerators, such as the MI2XX, the UTCL1 does not count hit-on-miss requests.
Vector L1 Cache RAM or Texture Cache (TC)#
After coalescing in the address processing unit of the v1LD, and address translation in the L1 TLB the request proceeds to the Cache RAM stage of the pipeline. Incoming requests are looked up in the cache RAMs using parts of the physical address as a tag. Hits will be returned through the data-return path, while misses will routed out to the L2 Cache for servicing.
The metrics tracked by the vL1D RAM include:
vL1D cache stall metrics#
The vL1D also reports where it is stalled in the pipeline, which may indicate performance limiters of the cache. A stall in the pipeline may result in backpressuring earlier parts of the pipeline, e.g., a stall on L2 requests may backpressure the wave-issue logic of the VMEM pipe and prevent it from issuing more vector memory instructions until the vL1D’s outstanding requests are completed.
Metric |
Description |
Unit |
|---|---|---|
Stalled on L2 Data |
The ratio of the number of cycles where the vL1D is stalled waiting for requested data to return from the L2 cache divided by the number of cycles where the vL1D is active [2]. |
Percent |
Stalled on L2 Requests |
The ratio of the number of cycles where the vL1D is stalled waiting to issue a request for data to the L2 cache divided by the number of cycles where the vL1D is active [2]. |
Percent |
Tag RAM Stall (Read/Write/Atomic) |
The ratio of the number of cycles where the vL1D is stalled due to Read/Write/Atomic requests with conflicting tags being looked up concurrently, divided by the number of cycles where the vL1D is active [2]. |
Percent |
vL1D cache access metrics#
The vL1D cache access metrics broadly indicate the type of requests incoming from the cache front-end, the number of requests that were serviced by the vL1D, and the number & type of outgoing requests to the L2 cache. In addition, this section includes the approximate latencies of accesses to the cache itself, along with latencies of read/write memory operations to the L2 cache.
Metric |
Description |
Unit |
|---|---|---|
Total Requests |
The total number of incoming requests from the address processing unit after coalescing. |
Requests |
Total read/write/atomic requests |
The total number of incoming read/write/atomic requests from the address processing unit after coalescing per normalization unit |
Requests per normalization unit |
Cache Bandwidth |
The number of bytes looked up in the vL1D cache as a result of VMEM instructions per normalization unit. The number of bytes is calculated as the number of cache lines requested multiplied by the cache line size. This value does not consider partial requests, so for instance, if only a single value is requested in a cache line, the data movement will still be counted as a full cache line. |
Bytes per normalization unit |
Cache Hit Rate [1] |
The ratio of the number of vL1D cache line requests that hit in vL1D cache over the total number of cache line requests to the vL1D Cache RAM. |
Percent |
Cache Accesses |
The total number of cache line lookups in the vL1D. |
Cache lines |
Cache Hits [1] |
The number of cache accesses minus the number of outgoing requests to the L2 cache, that is, the number of cache line requests serviced by the vL1D Cache RAM per normalization unit. |
Cache lines per normalization unit |
Invalidations |
The number of times the vL1D was issued a write-back invalidate command
during the kernel’s execution per
normalization unit. This may be triggered
by, for instance, the |
Invalidations per normalization unit |
L1-L2 Bandwidth |
The number of bytes transferred across the vL1D-L2 interface as a result of VMEM instructions, per normalization unit. The number of bytes is calculated as the number of cache lines requested multiplied by the cache line size. This value does not consider partial requests, so for instance, if only a single value is requested in a cache line, the data movement will still be counted as a full cache line. |
Bytes per normalization unit |
L1-L2 Reads |
The number of read requests for a vL1D cache line that were not satisfied by the vL1D and must be retrieved from the to the L2 Cache per normalization unit. |
Requests per normalization unit |
L1-L2 Writes |
The number of write requests to a vL1D cache line that were sent through the vL1D to the L2 cache, per normalization unit. |
Requests per normalization unit |
L1-L2 Atomics |
The number of atomic requests that are sent through the vL1D to the L2 cache, per normalization unit. This includes requests for atomics with, and without return. |
Requests per normalization unit |
L1 Access Latency |
Calculated as the average number of cycles that a vL1D cache line request spent in the vL1D cache pipeline. |
Cycles |
L1-L2 Read Access Latency |
Calculated as the average number of cycles that the vL1D cache took to issue and receive read requests from the L2 Cache. This number also includes requests for atomics with return values. |
Cycles |
L1-L2 Write Access Latency |
Calculated as the average number of cycles that the vL1D cache took to issue and receive acknowledgement of a write request to the L2 Cache. This number also includes requests for atomics without return values. |
Cycles |
Note
All cache accesses in vL1D are for a single cache line’s worth of data. The size of a cache line may vary, however on current AMD Instinct MI CDNA accelerators and GCN™ GPUs the L1 cache line size is 64B.
Footnotes
vL1D - L2 Transaction Detail#
This section provides a more granular look at the types of requests made to the L2 cache. These are broken down by the operation type (read / write / atomic, with, or without return), and the memory type.
Vector L1 data-return path or Texture Data (TD)#
The data-return path of the vL1D cache, also known as the Texture Data (TD) unit, is responsible for routing data returned from the vL1D cache RAM back to a wavefront on a SIMD. As described in the vL1D cache front-end section, the data-return path is passed information about the space requirements and routing for data requests from the VALU. When data is returned from the vL1D cache RAM, it is matched to this previously stored request data, and returned to the appropriate SIMD.
Omniperf reports the following vL1D data-return path metrics:
Metric |
Description |
Unit |
|---|---|---|
Data-return Busy |
Percent of the total CU cycles the data-return unit was busy processing or waiting on data to return to the CU. |
Percent |
Cache RAM → Data-return Stall |
Percent of the total CU cycles the data-return unit was stalled on data to be returned from the vL1D Cache RAM. |
Percent |
Workgroup manager → Data-return Stall |
Percent of the total CU cycles the data-return unit was stalled by the workgroup manager due to initialization of registers as a part of launching new workgroups. |
Percent |
Coalescable Instructions |
The number of instructions submitted to the data-return unit by the address processor that were found to be coalescable, per normalization unit. |
Instructions per normalization unit |
Read Instructions |
The number of read instructions submitted to the data-return unit by the address processor summed over all compute units on the accelerator, per normalization unit. This is expected to be the sum of global/generic and spill/stack reads in the address processor. |
Instructions per normalization unit |
Write Instructions |
The number of store instructions submitted to the data-return unit by the address processor summed over all compute units on the accelerator, per normalization unit. This is expected to be the sum of global/generic and spill/stack stores counted by the vL1D cache-front-end. |
Instructions per normalization unit |
Atomic Instructions |
The number of atomic instructions submitted to the data-return unit by the address processor summed over all compute units on the accelerator, per normalization unit. This is expected to be the sum of global/generic and spill/stack atomics in the address processor. |
Instructions per normalization unit |