Compute unit (CU)#
The compute unit (CU) is responsible for executing a user’s kernels on CDNA™-based accelerators. All wavefronts of a workgroup are scheduled on the same CU.
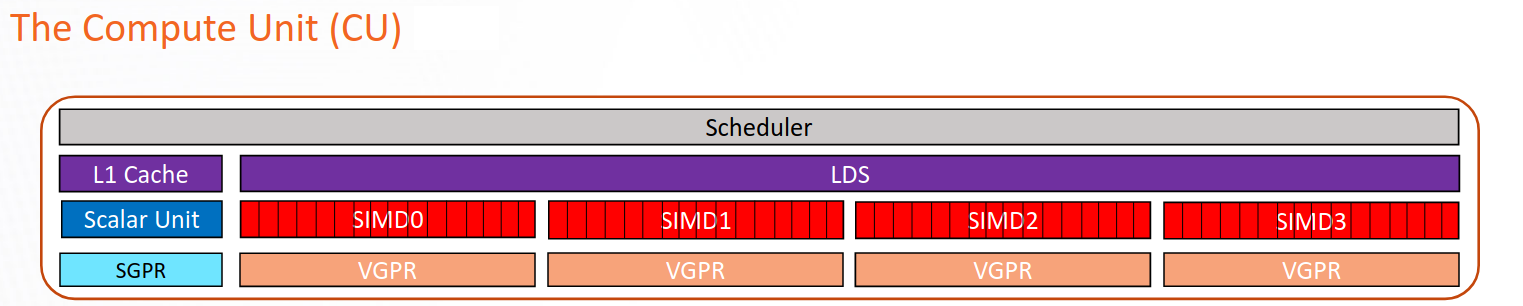
The CU consists of several independent execution pipelines and functional units. The Pipeline descriptions section details the various execution pipelines – VALU, SALU, LDS, scheduler, and so forth. The metrics presented by ROCm Compute Profiler for these pipelines are described in Pipeline metrics. The vL1D cache and LDS are described in their own sections.
The Vector arithmetic logic unit (VALU) is composed of multiple SIMD (single instruction, multiple data) vector processors, vector general purpose registers (VGPRs) and instruction buffers. The VALU is responsible for executing much of the computational work on CDNA accelerators, including but not limited to floating-point operations (FLOPs) and integer operations (IOPs).
The vector memory (VMEM) unit is responsible for issuing loads, stores and atomic operations that interact with the memory system.
The Scalar arithmetic logic unit (SALU) is shared by all threads in a wavefront, and is responsible for executing instructions that are known to be uniform across the wavefront at compile time. The SALU has a memory unit (SMEM) for interacting with memory, but it cannot issue separately from the SALU.
The Local data share (LDS) is an on-CU software-managed scratchpad memory that can be used to efficiently share data between all threads in a workgroup.
The Scheduler is responsible for issuing and decoding instructions for all the wavefronts on the compute unit.
The vector L1 data cache (vL1D) is the first level cache local to the compute unit. On current CDNA accelerators, the vL1D is write-through. The vL1D caches from multiple compute units are kept coherent with one another through software instructions.
CDNA accelerators – that is, AMD Instinct™ MI100 and newer – contain specialized matrix-multiplication accelerator pipelines known as the Matrix fused multiply-add (MFMA).
For a more in-depth description of a compute unit on a CDNA accelerator, see Introduction to AMD GPU Programming with HIP (slide 22) and The AMD GCN Architecture - A Crash Course (slide 27).