Profiling and debugging#
2024-06-17
11 min read time
This section discusses profiling and debugging tools and some of their common usage patterns with ROCm applications.
PyTorch Profiler#
PyTorch Profiler can be invoked inside Python scripts, letting you collect CPU and GPU performance metrics while the script is running. See the PyTorch Profiler tutorial for more information.
You can then visualize and view these metrics using an open-source profile visualization tool like Perfetto UI.
Use the following snippet to invoke PyTorch Profiler in your code.
import torch import torchvision.models as models from torch.profiler import profile, record_function, ProfilerActivity model = models.resnet18().cuda() inputs = torch.randn(2000, 3, 224, 224).cuda() with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof: with record_function("model_inference"): model(inputs) prof.export_chrome_trace("resnet18_profile.json")
Profile results in
resnet18_profile.jsoncan be viewed by the Perfetto visualization tool. Go to https://ui.perfetto.dev and import the file. In your Perfetto visualization, you’ll see that the upper section shows transactions denoting the CPU activities that launch GPU kernels while the lower section shows the actual GPU activities where it processes theresnet18inferences layer by layer.
Fig. 10 Perfetto trace visualization example.#
ROCm profiling tools#
Heterogenous systems, where programs run on both CPUs and GPUs, introduce additional complexities. Understanding the critical path and kernel execution is all the more important; so, performance tuning is a necessary component in the benchmarking process.
With AMD’s profiling tools, developers are able to gain important insight into how efficiently their application is using hardware resources and effectively diagnose potential bottlenecks contributing to poor performance. Developers working with AMD Instinct accelerators have multiple tools depending on their specific profiling needs; these are:
ROCProfiler#
ROCProfiler is primarily a low-level API for accessing and extracting GPU hardware performance metrics, commonly called performance counters. These counters quantify the performance of the underlying architecture showcasing which pieces of the computational pipeline and memory hierarchy are being utilized.
Your ROCm installation contains a script or executable command called rocprof which provides the ability to list all
available hardware counters for your specific accelerator or GPU, and run applications while collecting counters during
their execution.
This rocprof utility also depends on the ROCTracer and ROC-TX libraries, giving it the
ability to collect timeline traces of the accelerator software stack as well as user-annotated code regions.
Note
rocprof is a CLI-only utility so input and output takes the format of .txt and CSV files. These
formats provide a raw view of the data and puts the onus on the user to parse and analyze. Therefore, rocprof
gives the user full access and control of raw performance profiling data, but requires extra effort to analyze the
collected data.
Omniperf#
Omniperf is a system performance profiler for high-performance computing (HPC) and machine learning (ML) workloads using Instinct accelerators. Under the hood, Omniperf uses ROCProfiler to collect hardware performance counters. The Omniperf tool performs system profiling based on all approved hardware counters for Instinct accelerator architectures. It provides high level performance analysis features including System Speed-of-Light, IP block Speed-of-Light, Memory Chart Analysis, Roofline Analysis, Baseline Comparisons, and more.
Omniperf takes the guesswork out of profiling by removing the need to provide text input files with lists of counters to collect and analyze raw CSV output files as is the case with ROC-profiler. Instead, Omniperf automates the collection of all available hardware counters in one command and provides a graphical interface to help users understand and analyze bottlenecks and stressors for their computational workloads on AMD Instinct accelerators.
Note
Omniperf collects hardware counters in multiple passes, and will therefore re-run the application during each pass to collect different sets of metrics.
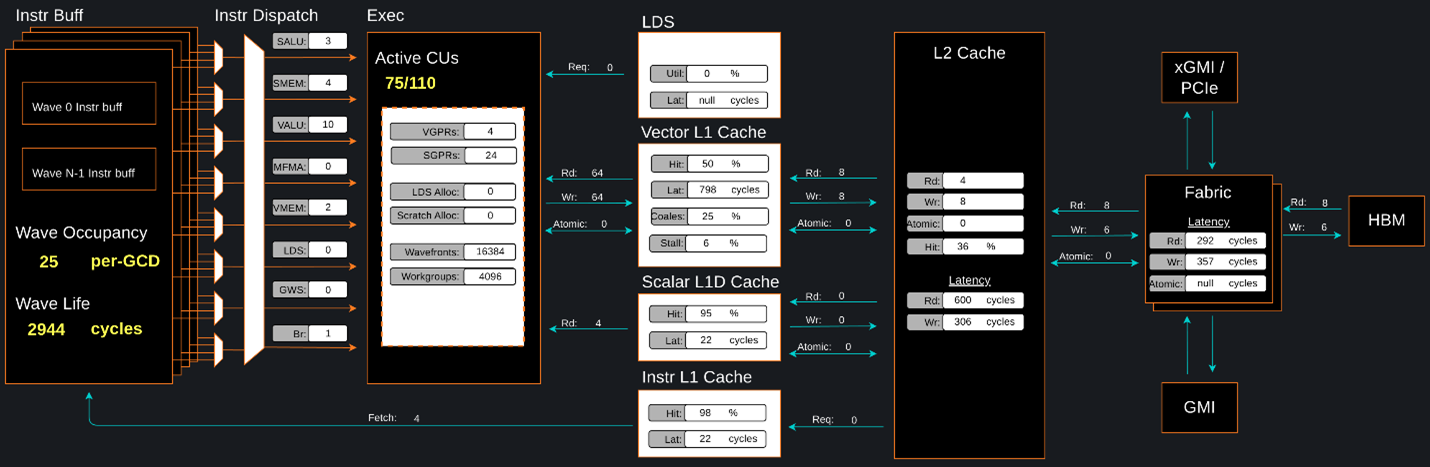
Fig. 11 Omniperf memory chat analysis panel.#
In brief, Omniperf provides details about hardware activity for a particular GPU kernel. It also supports both a web-based GUI or command-line analyzer, depending on your preference.
Omnitrace#
Omnitrace is a comprehensive profiling and tracing tool for parallel applications, including HPC and ML packages, written in C, C++, Fortran, HIP, OpenCL, and Python which execute on the CPU or CPU and GPU. It is capable of gathering the performance information of functions through any combination of binary instrumentation, call-stack sampling, user-defined regions, and Python interpreter hooks.
Omnitrace supports interactive visualization of comprehensive traces in the web browser in addition to high-level
summary profiles with mean/min/max/stddev statistics. Beyond runtime
information, Omnitrace supports the collection of system-level metrics such as CPU frequency, GPU temperature, and GPU
utilization. Process and thread level metrics such as memory usage, page faults, context switches, and numerous other
hardware counters are also included.
Tip
When analyzing the performance of an application, it is best not to assume you know where the performance bottlenecks are and why they are happening. Omnitrace is the ideal tool for characterizing where optimization would have the greatest impact on the end-to-end execution of the application and to discover what else is happening on the system during a performance bottleneck.
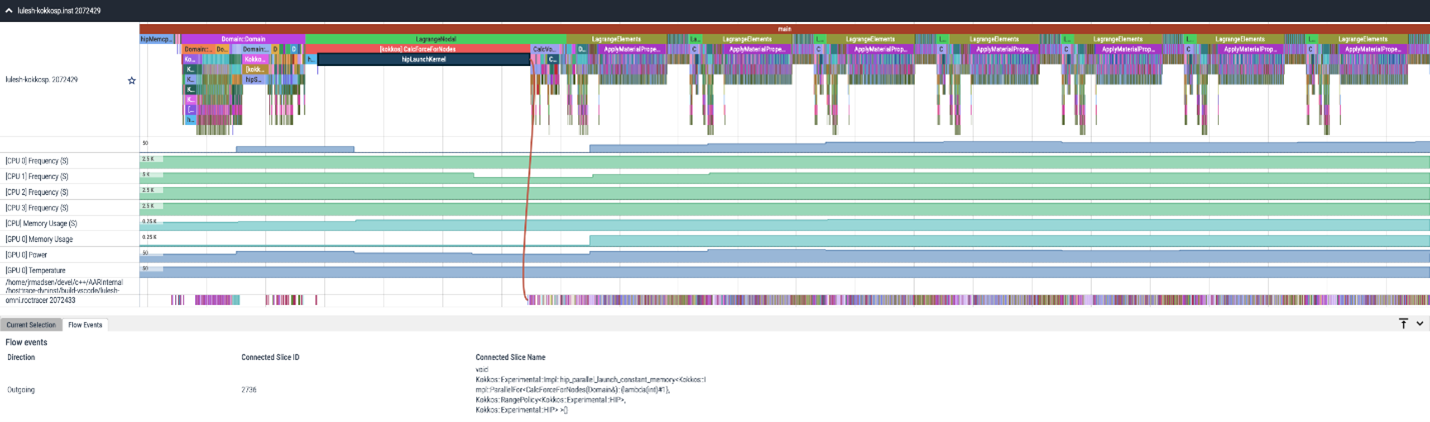
Fig. 12 Omnitrace timeline trace example.#
For details usage and examples of using these tools, refer to the Introduction to profiling tools for AMD hardware developer blog.
Debugging with ROCr Debug Agent#
ROCr Debug Agent) is a library that can be loaded by the ROCm platform runtime (ROCr) to provide the following functionalities for all AMD accelerators and GPUs supported by the ROCm Debugger API (ROCdbgapi).
Print the state of all AMD accelerator or GPU wavefronts that caused a queue error; for example, causing a memory violation, executing an
s_trap2, or executing an illegal instruction.Print the state of all AMD accelerator or GPU wavefronts by sending a
SIGQUITsignal to the process in question; for example, by pressingCtrl + \while the process is executing.
Debugging memory access faults#
Identifying a faulting kernel is often enough to triage a memory access fault. To that end, the ROCr Debug Agent can trap a memory access fault and provide a dump of all active wavefronts that caused the error as well as the name of the kernel. The ROCr Debug Agent Library README provides full instructions, but in brief:
Compiling with
-ggdb -O0is recommended but not required.HSA_TOOLS_LIB=/opt/rocm/lib/librocm-debug-agent.so.2 HSA_ENABLE_DEBUG=1 ./my_program
When the debug agent traps the fault, it will produce an extremely verbose output of all wavefront registers and memory content. Importantly, it also prints something like:
Disassembly for function vector_add_assert_trap(int*, int*, int*):
code object:
file:////rocm-debug-agent/build/test/rocm-debug-agent-test#offset=14309&size=31336
loaded at: [0x7fd4f100c000-0x7fd4f100e070]
The kernel name and the code object file should be listed. In the
example above, the kernel name is vector_add_assert_trap, but this might
also look like:
Disassembly for function memory:///path/to/codeobject#offset=1234&size=567:
In this case, it is an in-memory kernel that was generated at runtime.
Using the following environment variable, the debug agent will save all code objects to the current directory (use
--save-code-objects=[DIR] to place them in another location). The code objects will be renamed from the URI format
with special characters replaced by _.
ROCM_DEBUG_AGENT_OPTIONS="--all --save-code-objects"
Use the llvm-objdump command to disassemble the indicated in-memory
code object that has now been saved to disk. The name of the kernel is
often found inside the disassembled code object.
llvm-objdump --disassemble-all path/to/code-object.co
Consider turning off memory caching strategies both within the ROCm stack and PyTorch where possible. This will give the debug agent the best chance at finding the memory fault where it originates. Otherwise, it could be masked by writing past the end of a cached block within a larger allocation.
PYTORCH_NO_HIP_MEMORY_CACHING=1
HSA_DISABLE_FRAGMENT_ALLOCATOR=1