Conceptual overview of fine-tuning LLMs#
2024-09-12
8 min read time
Large language models (LLMs) are trained on massive amounts of text data to generate coherent and fluent text. The underlying transformer architecture is the fundamental building block of all LLMs. Transformers enable LLMs to understand and generate text by capturing contextual relationships and long-range dependencies. To better understand the philosophy of the transformer architecture, review the foundational Attention is all you need paper.
By further training pre-trained LLMs, the fine-tuned model can gain knowledge related to specific fields or tasks, thereby significantly improving its performance in that field or task. The core idea of fine-tuning is to use the parameters of the pre-trained model as the starting point for new tasks and shape it through a small amount of specific domain or task data, expanding the original model’s capability to new tasks or datasets.
Fine-tuning can effectively improve the performance of existing pre-trained models in specific application scenarios. Continuous training and adjustment of the parameters of the base model in the target domain or task can better capture the semantic characteristics and patterns in specific scenarios, thereby significantly improving the key indicators of the model in that domain or task. For example, by fine-tuning the Llama 2 model, its performance in certain applications can be improve over the base model.
The challenge of fine-tuning models#
However, the computational cost of fine-tuning is still high, especially for complex models and large datasets, which poses distinct challenges related to substantial computational and memory requirements. This might be a barrier for accelerators or GPUs with low computing power or limited device memory resources.
For example, suppose we have a language model with 7 billion (7B) parameters, represented by a weight matrix \(W\). During backpropagation, the model needs to learn a \(ΔW\) matrix, which updates the original weights to minimize the value of the loss function.
The weight update is as follows: \(W_{updated} = W + ΔW\).
If the weight matrix \(W\) contains 7B parameters, then the weight update matrix \(ΔW\) should also contain 7B parameters. Therefore, the \(ΔW\) calculation is computationally and memory intensive.
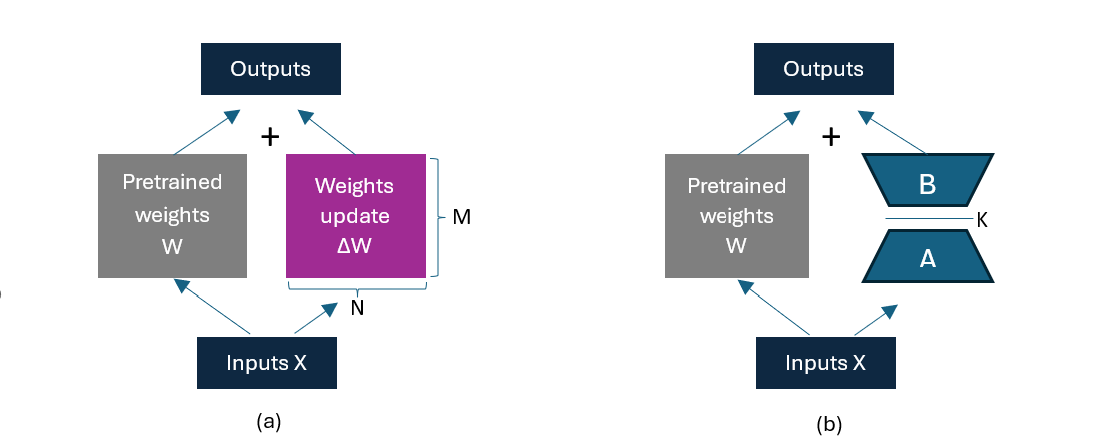
(a) Weight update in regular fine-tuning. (b) Weight update in LoRA where the product of matrix A (\(M\times K\)) and matrix B (\(K\times N\)) is \(ΔW(M\times N)\); dimension K is a hyperparameter. By representing \(ΔW\) as the product of two smaller matrices (A and B) with a lower rank K, the number of trainable parameters is significantly reduced.#
Optimizations for model fine-tuning#
Low-Rank Adaptation (LoRA) is a technique allowing fast and cost-effective fine-tuning of state-of-the-art LLMs that can overcome this issue of high memory consumption.
LoRA accelerates the adjustment process and reduces related memory costs. To be precise, LoRA decomposes the portion of weight changes \(ΔW\) into high-precision low-rank representations, which do not require the calculations of all \(ΔW\). It learns the decomposition representation of \(ΔW\) during training, as shown in the weight update diagram. This is how LoRA saves on computing resources.
LoRA is integrated into the Hugging Face Parameter-Efficient Fine-Tuning (PEFT) library, as well as other computation and memory efficiency optimization variants for model fine-tuning such as AdaLoRA. This library efficiently adapts large pre-trained models to various downstream applications without fine-tuning all model parameters. PEFT methods only fine-tune a few model parameters, significantly decreasing computational and storage costs while yielding performance comparable to a fully fine-tuned model. PEFT is integrated with the Hugging Face Transformers library, providing a faster and easier way to load, train, and use large models for inference.
To simplify running a fine-tuning implementation, the Transformer Reinforcement Learning (TRL) library provides a set of tools to train transformer language models with
reinforcement learning, from the Supervised Fine-Tuning step (SFT), Reward Modeling step (RM), to the Proximal Policy
Optimization (PPO) step. The SFTTrainer API in TRL encapsulates these PEFT optimizations so you can easily import
their custom training configuration and run the training process.
Walkthrough#
To demonstrate the benefits of LoRA and the ideal compute compatibility of using PEFT and TRL libraries on AMD ROCm-compatible accelerators and GPUs, let’s step through a comprehensive implementation of the fine-tuning process using the Llama 2 7B model with LoRA tailored specifically for question-and-answer tasks on AMD MI300X accelerators.
Before starting, review and understand the key components of this walkthrough:
Llama 2: a family of large language models developed and publicly released by Meta. Its variants range in scale from 7 billion to 70 billion parameters.
Fine-tuning: a critical process that refines LLMs for specialized tasks and optimizes performance.
LoRA: a memory-efficient implementation of LLM fine-tuning that significantly reduces the number of trainable parameters.
SFTTrainer: an optimized trainer with a simple interface to easily fine-tune pre-trained models with PEFT adapters, for example, LoRA, for memory efficiency purposes on a custom dataset.
Continue the walkthrough in Fine-tuning and inference.