Optimizing Triton kernels#
2024-06-27
18 min read time
This section introduces the general steps for Triton kernel optimization. Broadly, Triton kernel optimization is similar to HIP and CUDA kernel optimization.
Memory access efficiency#
The accelerator or GPU contains global memory, local data share (LDS), and registers. Global memory has high access latency, but is large. LDS access has much lower latency, but is smaller. Register access is the fastest yet smallest among the three.
So, the data in global memory should be loaded and stored as few times as possible. If different threads in a block need to access the same data, these data should be first transferred from global memory to LDS, then accessed by different threads in a workgroup.
Hardware resource utilization#
Each accelerator or GPU has multiple Compute Units (CUs) and various CUs do computation in parallel. So, how many CUs can a compute kernel can allocate its task to? For the AMD MI300X accelerator, the grid should have at least 1024 thread blocks or workgroups.
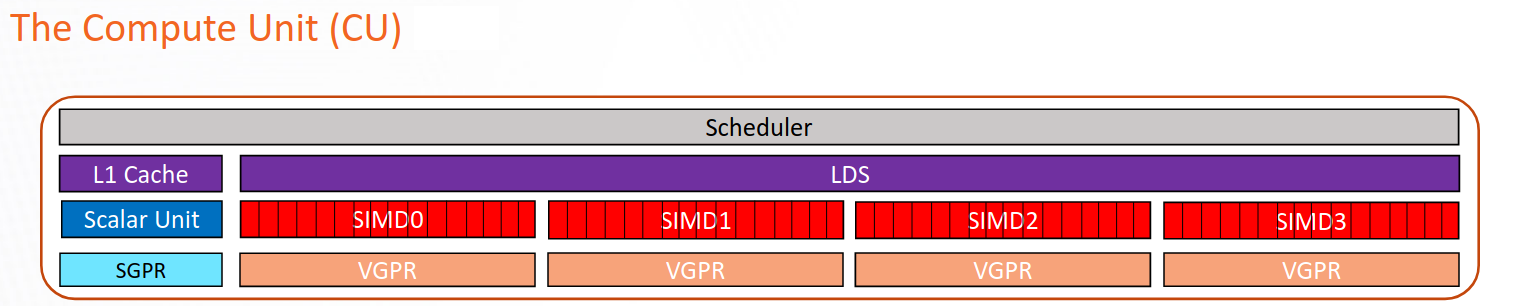
Fig. 9 Schematic representation of a CU in the CDNA2 or CDNA3 architecture.#
To increase hardware utilization and maximize parallelism, it is necessary to design algorithms that can exploit more parallelism. One approach to achieving this is by using larger split-K techniques for General Matrix Multiply (GEMM) operations, which can further distribute the computation across more CUs, thereby enhancing performance.
Tip
You can query hardware resources with the command rocminfo (in the /opt/rocm/bin directory). For instance,
query the number of CUs, number of SIMD, and wavefront size using the following commands.
rocminfo | grep "Compute Unit"
rocminfo | grep "SIMD"
rocminfo | grep "Wavefront Size"
On an MI300X device, there are 304 CUs, 4 SIMD per CU, and the wavefront size (warp size) is 64. See Hardware specifications for a full list of AMD accelerators and GPUs.
IR analysis#
In Triton, there are several layouts including blocked, shared, sliced, and MFMA.
From the Triton GPU IR (intermediate representation), you can know in which memory each computation is
performed. The following is a snippet of IR from the Flash Attention decode int4 key-value program. It is to
de-quantize the int4 key-value from the int4 data type to fp16.
%190 = tt.load %189 {cache = 1 : i32, evict = 1 : i32, isVolatile =
false} : tensor<1x64xi32, #blocked6> loc(#loc159)
%266 = arith.andi %190, %cst_28 : tensor<1x64xi32, #blocked6>
loc(#loc250)
%267 = arith.trunci %266 : tensor<1x64xi32, #blocked6> to
tensor<1x64xi16, #blocked6> loc(#loc251)
%268 = tt.bitcast %267 : tensor<1x64xi16, #blocked6> -> tensor<1x64xf16,
#blocked6> loc(#loc252)
%269 = triton_gpu.convert_layout %268 : (tensor<1x64xf16, #blocked6>) ->
tensor<1x64xf16, #shared1> loc(#loc252)
%270 = tt.trans %269 : (tensor<1x64xf16, #shared1>) -> tensor<64x1xf16,
#shared2> loc(#loc194)
%276 = triton_gpu.convert_layout %270 : (tensor<64x1xf16, #shared2>) ->
tensor<64x1xf16, #blocked5> loc(#loc254)
%293 = arith.mulf %276, %cst_30 : tensor<64x1xf16, #blocked5>
loc(#loc254)
%295 = arith.mulf %292, %294 : tensor<64x32xf16, #blocked5> loc(#loc264)
%297 = arith.addf %295, %296 : tensor<64x32xf16, #blocked5> loc(#loc255)
%298 = triton_gpu.convert_layout %297 : (tensor<64x32xf16, #blocked5>)
-> tensor<64x32xf16, #shared1> loc(#loc255)
%299 = tt.trans %298 : (tensor<64x32xf16, #shared1>) ->
tensor<32x64xf16, #shared2> loc(#loc196)
%300 = triton_gpu.convert_layout %299 : (tensor<32x64xf16, #shared2>) ->
tensor<32x64xf16, #triton_gpu.dot_op<{opIdx = 1, parent = #mfma, kWidth
= 4}>> loc(#loc197)
From the IR, you can see i32 data is loaded from global memory to registers. With a few element-wise operations in
registers, then it is stored in shared memory for the transpose operation, which needs data movement across different
threads. With the transpose done, it is loaded from LDS to register again, and with a few more element-wise operations,
they are stored in LDS again. The last step is to load from LDS to registers and convert to the dot-operand layout.
From the IR, you can see that it uses the LDS twice: one for the transpose, and the other to convert the blocked layout to a dot-operand layout.
Assembly analysis#
In the ISA, ensure global_load_dwordx4 is used, especially when the
load happens in a loop.
In most cases, the LDS load and store should use _b128 as well to
minimize the number of LDS access instructions. Note that upstream (or backend) might not have _b128 LDS read/write,
so it uses _b64. For most cases, no matter if you use fork or upstream,
the LDS access should have _b64 vector width.
The AMD ISA has the s_waitcnt instruction to synchronize the dependency
of memory access and computations. The s_waitcnt instruction can
have two signals, typically in the context of Triton:
lgkmcnt(n):lgkm stands for LDS, GDS, Constant and Message.In this context, it is often related to LDS access. The number
nhere means the number of such accesses that can be left out to continue. For example, 0 means alllgkmaccess must finish before continuing, and 1 means only 1lgkmaccess can be still running asynchronously before proceeding.vmcnt(n):vm means vector memory.This happens when vector memory is accessed, for example, when global load moves from global memory to vector memory. Again, the number
nhere means the number of accesses that can be left out to continue.
Generally recommended guidelines are as follows.
Vectorize memory access as much as possible.
Ensure synchronization is done efficiently.
Overlap of instructions to hide latency, but it requires thoughtful analysis of the algorithms.
If you find inefficiencies, you can trace it back to LLVM IR, TTGIR and even TTIR to see where the problem comes from. If you find it during compiler optimization, activate the MLIR dump and check which optimization pass caused the problem.
Kernel occupancy#
Get the VGPR count, search for
.vgpr_countin the ISA (for example,N).Get the allocated LDS following the steps (for example, L for the kernel).
export MLIR_ENABLE_DUMP=1rm -rf ~/.triton/cachepython kernel.py | | grep "triton_gpu.shared = " | tail -n 1You should see something like
triton_gpu.shared = 65536, indicating 65536 bytes of LDS are allocated for the kernel.
Get number of waves per workgroup using the following steps (for example,
nW).export MLIR_ENABLE_DUMP=1rm -rf ~/.triton/cachepython kernel.py | | grep "triton_gpu.num-warps " | tail -n 1You should see something like
“triton_gpu.num-warps" = 8, indicating 8 waves per workgroup.
Compute occupancy limited by VGPR based on N according to the following table. For example, waves per EU as
occ_vgpr.
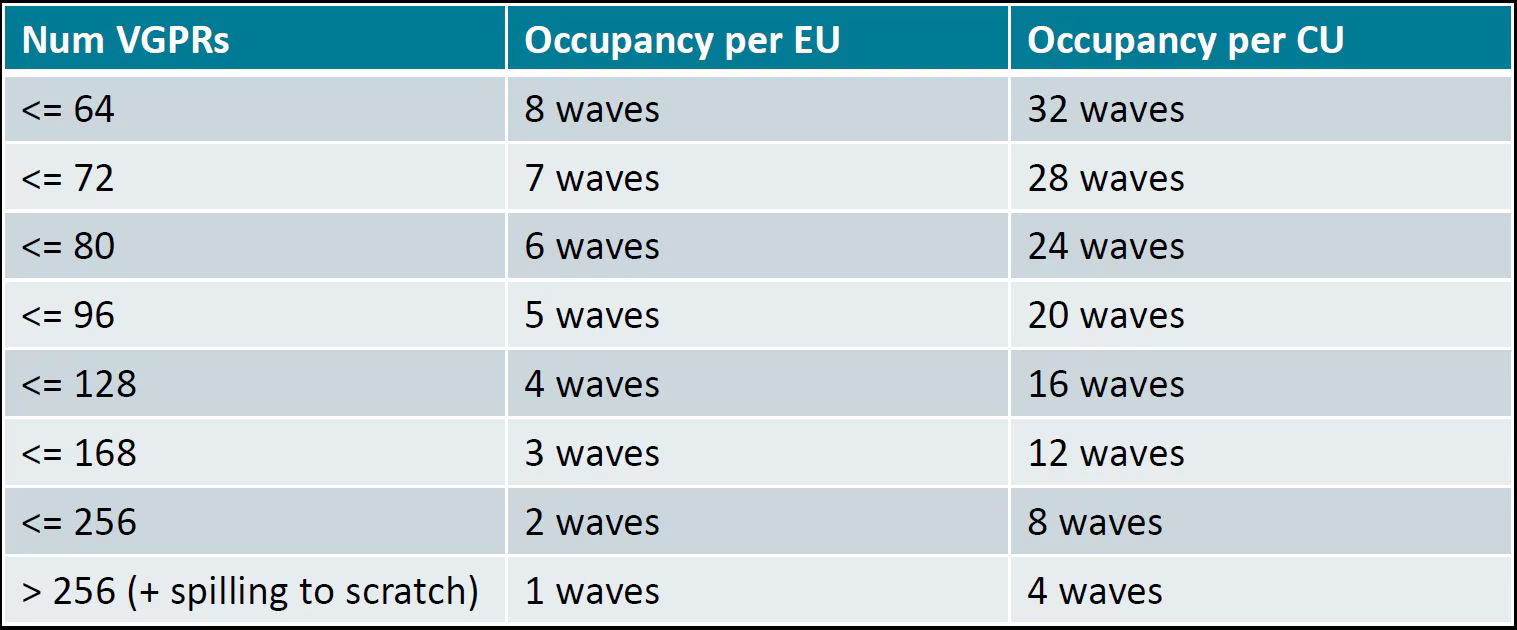
Compute occupancy limited by LDS based on L by:
occ_lds = floor(65536 / L).Then the occupancy is
occ = min(floor(occ_vgpr * 4 / nW), occ_lds) * nW / 4occ_vgpr \* 4gives the total number of waves on all 4 execution units (SIMDs) per CU.floor(occ_vgpr * 4 / nW)gives the occupancy of workgroups per CU regrading VGPR usage.The true
occis the minimum of the two.
Auto-tunable kernel configurations and environment variables#
This section relates to the amount of memory access and computation assigned to each CU. It is related to the usage of LDS, registers and the scheduling of different tasks on a CU.
The following is a list of kernel arguments used for tuning.
num_stages=nAdjusts the number of pipeline stages for different types of kernels. On AMD accelerators, set
num_stagesaccording to the following rules:For kernels with a single GEMM, set to
0.For kernels with two GEMMs fused (Flash Attention, or any other kernel that fuses 2 GEMMs), set to
1.For kernels that fuse a single GEMM with another non-GEMM operator (for example ReLU activation), set to
0.For kernels that have no GEMMs, set to
1.
waves_per_eu=nHelps to manage Vector General Purpose Registers (VGPR) usage to achieve desired occupancy levels. This argument hints to the compiler to reduce VGPR to achieve
noccupancy. See Kernel occupancy for more information about how to compute occupancy.This argument is useful if:
The occupancy of the kernel is limited by VGPR usage.
The current VGPR usage is only a few above a boundary in Occupancy related to VGPR usage in an Instinct MI300X accelerator.
For example, according to the table, the available VGPR is 512 per Execution Unit (EU), and VGPU is allocated at the unit of 16. If the current VGPR usage is 170, the actual requested VGPR will be 176, so the occupancy is only 2 waves per CU since \(176 \times 3 > 512\). So, if you set
waves_per_euto 3, the LLVM backend tries to bring VGPR usage down so that it might fit 3 waves per EU.BLOCK_M,BLOCK_N,BLOCK_KTile sizes to be tuned to balance the memory-to-computation ratio. You want tile sizes large enough to maximize the efficiency of memory-to-computation ratio, but small enough to parallelize the greatest number of workgroups at the grid level.
matrix_instr_nonkdimExperimental feature for Flash Attention-like kernels that determines the size of the Matrix Fused Multiply-Add (MFMA) instruction used.
Matrix_instr_nonkdim = 16:mfma_16x16is used.Matrix_instr_nonkdim = 32:mfma_32x32is used.
For GEMM kernels on an AMD MI300X accelerator,
mfma_16x16typically outperformsmfma_32x32, even for large tile/GEMM sizes.
The following is an environment variable used for tuning.
OPTIMIZE_EPILOGUESetting this variable to
1can improve performance by removing theconvert_layoutoperation in the epilogue. It should be turned on (set to1) in most cases. SettingOPTIMIZE_EPILOGUE=1stores the MFMA instruction results in the MFMA layout directly; this comes at the cost of reduced global store efficiency, but the impact on kernel execution time is usually minimal.By default (
0), the results of MFMA instruction are converted to blocked layout, which leads toglobal_storewith maximum vector length, that isglobal_store_dwordx4.This is done implicitly with LDS as the intermediate buffer to achieve data exchange between threads. Padding is used in LDS to avoid bank conflicts. This usually leads to extra LDS usage, which might reduce occupancy.
Note
This variable is not turned on by default because it only works with
tt.storebut nottt.atomic_add, which is used in split-k and stream-k GEMM kernels. In the future, it might be enabled withtt.atomic_addand turned on by default.See IR analysis.
TorchInductor with Triton tuning knobs#
The following are suggestions for optimizing matrix multiplication (GEMM) and convolution (conv) operations in PyTorch
using inductor, a part of the PyTorch compilation framework. The goal is to leverage Triton to achieve better
performance.
Learn more about TorchInductor environment variables and usage in PyTorch documentation.
To enable a gemm/conv lowering to Triton, it requires use of inductor’s max_autotune mode. This benchmarks a
static list of Triton configurations (conv configurations for max auto-tune + matmul configurations for max
auto-tune) and uses the fastest for each shape. Note that the Triton is not used if regular MIOpen
or rocBLAS is faster for a specific operation.
Set
torch._inductor.config.max_autotune = TrueorTORCHINDUCTOR_MAX_AUTOTUNE=1.Or, for more fine-grained control:
torch._inductor.config.max_autotune.pointwise = TrueTo enable tuning for
pointwise/reductionops.torch._inductor.config.max_autotune_gemm = TrueTo enable tuning or lowering of
mm/convs.torch._inductor.max_autotune_gemm_backends/TORCHINDUCTOR_MAX_AUTOTUNE_GEMM_BACKENDSTo select the candidate backends for
mmauto-tuning. Defaults toTRITON,ATEN,NV. This also includes theCUTLASStuning option. Limiting this toTRITONmight improve performance by enabling more fusedmmkernels instead of going to rocBLAS.
For
mmtuning, tuningcoordinate_descentmight improve performance.torch._inductor.config.coordinate_descent_tuning = TrueorTORCHINDUCTOR_COORDINATE_DESCENT_TUNING=1Inference can see large improvements on AMD GPUs by utilizing
torch._inductor.config.freezing=Trueor theTORCHINDUCTOR_FREEZING=1variable, which in-lines weights as constants and enables constant folding optimizations.Enabling
inductor’s cpp_wrapper might improve overhead. This generates C++ code which launches Triton binaries directly withhipModuleLaunchKerneland relies on hipification.For NHWC convolutions workloads
torch._inductor.config.layout_optimization=TrueorTORCHINDUCTOR_LAYOUT_OPTIMIZATION=can help be enforcing channels_last format throughout the graph avoiding any additional transposes added byinductor. Note thatPYTORCH_MIOPEN_SUGGEST_NHWC=1is recommended if using this.Extracting the Triton kernel
TORCH_COMPILE_DEBUGcreates atorch_compile_debug/directory at current path, in theoutput_code.pythe code-strings for the Triton kernels that are defined. Manual work is then required to strip out the kernel and create kernel compilation and launch via Triton.
Other guidelines#
Performance-critical HIP provides an environment variable,
export HIP_FORCE_DEV_KERNARG=1, that can put HIP kernel arguments directly to device memory to reduce the latency of accessing kernel arguments. It can reduce 2 to 3 μs for some kernels. Setting this variable for the FA decode containingsplitKand reduced kernels can reduce the total time by around 6 μs in the benchmark test.Set the clock to deterministic. Use the command
rocm-smi --setperfdeterminism 1900to set the max clock speed to 1900MHz instead of the default 2100MHz. This can reduce the chance of clock speed decrease due to chip high temperature by setting a lower cap. You can restore this setting to its default value withrocm-smi -r.Set Non-Uniform Memory Access (NUMA) auto-balance. Run the command
cat /proc/sys/kernel/numa_balancingto check the current setting. An output of0indicates this setting is available. If output is1, run the commandsudo sh -c \\'echo 0 > /proc/sys/kernel/numa_balancingto set this.
For these settings, the env_check.sh script automates the setting, resetting, and checking of the such
environments. Find the script at ROCm/triton.
TunableOp#
TunableOp is a feature used to define and optimize kernels that can have tunable parameters. This is useful in optimizing the performance of custom kernels by exploring different parameter configurations to find the most efficient setup. See more about PyTorch TunableOp Model acceleration libraries.
You can easily manipulate the behavior TunableOp through environment variables, though you could use the C++ interface
at::cuda::tunable::getTuningContext(). A Python interface to the TuningContext does not yet exist.
The default value is 0, which means only 1 iteration is attempted. Remember: there’s an overhead to tuning. To try
and minimize the overhead, only a limited number of iterations of a given operation are attempted. If you set this to
10, each solution for a given operation can run as many iterations as possible within 10ms. There is a hard-coded
upper limit of 100 iterations attempted per solution. This is a tuning parameter; if you want the tunings to be chosen
based on an average over multiple iterations, increase the allowed tuning duration.